Calculate CD Variance and Relative Standard Errors
Calculate_CD_variance_and_relative_standard_error_(RSE).docx
Survey of Occupational Injuries and Illnesses
Calculate CD Variance and Relative Standard Errors
OMB: 1220-0045
DOCUMENTATION CHANGE VERSION CONTROL TABLE |
|||
Requirement Name |
Author |
Date |
Comments |
Calculate CD variance and relative standard error (RSE) |
Xingyou Zhang, Dee Zamora, Erin Huband, Michelle Myers, Jun Mize, Anurag Katare, Daniel Suh |
07/13/2023 |
Final requirement coming out of BigSOII Phase 3 |
|
|
|
|
|
|
|
|
|
|
|
|
USER STORY LOG |
|||
Topic |
User Story |
Iteration |
Notes |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Quality Characteristics (If applicable):
Requirements Acceptance Criteria:
(Guide to writing Requirements: Major distinct Components should include FR, NFR, and BR – discreet requirements… that testable. If the testing seems multipart, then break the Requirement)
Starting Point
After variances have been calculated for Annual Summary.
After estimation is completed for C&D.
Definitions and assumptions
This process generates sampling errors and variances for all counts (weighted estimates) and incidence rates for state and national levels.
The C&D uses a Taylor series linearization methodology to calculate estimates of standard errors for published core C&D estimates.
These requirements go into a lot of detail on when to roll-up and use a higher aggregate TEI for several calculations. Additional information about how to roll-up is in APPENDIX A at the end of this requirement.
What determines when to roll-up should be the same in Annual Summary as in Case and Demographic variance calculations. The only variables that are different from Annual Summary are those calculated for the z variables that are unique to case and demographic estimates.
When counting establishments in the sampling stratum use the sampled/original size class as the reported size class and count the number of establishments in the sampling stratum based on the sampled/original size class.
The N, n, owi, wi, y parts of the equations below should use the establishment dataset generated from the C&D extract program to do the calculations in the formulas throughout the requirements. The calculations for any z variables should use the FCW, finalcases, and the OIICS precategory datasets to do the calculations in the formulas below.
Inputs
SAS Datasets with the last successful Process ID
FCW DatasetFinalcases SAS dataset
SAS dataset after estimation is completed
The 5 OIICS precategory datasets
TEI Aggregate Levels
SAS dataset with variance information from Annual Summary
Establishment dataset from the C&D extract process that contains all establishments in the sample including mining, railroad, and dummy/prorated establishments from Annual Summary. The original sample weight and the summary final weight variables will be in this dataset to use for the formula calculations and determining if the roll-ups are needed.
Processing Steps
Estimation domains for both national and state estimates are combinations of estimation strata.
For total by total, an estimation stratum is defined by collection year, FIPS state code, ownership code, TEI, reported size class, and case type.
For one-way estimates, an estimation stratum is defined by collection year, FIPS state code, ownership code, TEI, reported size class, and case type, characteristic.
For two-way estimates, an estimation stratum is defined by collection year, FIPS state code, ownership code, TEI, reported size class, case type, characteristic, and cross characteristic.
Estimates are based the reported size class of the establishment (LDB Number). The number of usable establishments in an estimation stratum is based on the reported size class, not the size class used for sampling.
For variance estimates, calculate the estimate at the finest detail: collection year, FIPS state code, ownership code, TEI, reported size class, case type, characteristic, and cross characteristic. The variances of counts of broader levels are calculated as the sum of the finer levels that comprise the broad level. For example, the variance of counts of the collection year, FIPS state code, ownership code, TEI (i.e., reported size class 0), case type, characteristic, and cross characteristic is the sum of the variances of the collection year, FIPS state code, ownership code, TEI of reported size classes 1-5, case type, characteristic, and cross characteristic. For biennial estimates, the variance of counts of the FIPS state code, ownership code, TEI (i.e., reported size class 0), case type, characteristic, and cross characteristic is the sum of the variances of collection year 1, FIPS state code, ownership code, TEI of reported size classes 1-5, case type, characteristic, and cross characteristic and collection year 2, FIPS state code, ownership code, TEI of reported size classes 1-5, case type, characteristic, and cross characteristic.
The variances of rates of broader levels cannot be calculated as the sum of variances of the finer levels that comprise the broad level. Instead, they are calculated using all the usable establishments in the estimation domain. For example, the variance of the rate of the survey year, FIPS state code, ownership code, TEI (i.e., reported size class 0), case type, characteristic, and cross characteristic is calculated using all the usable establishments from size classes 1-5.
If the characteristic name and cross characteristic name for an estimate does not include TEI or TEI aggregate level, then use all industries for determining the calculations described below. Otherwise, match the usable establishments to the TEI or the TEI aggregate level in the characteristic or cross characteristic of the estimate and roll-up from there, if necessary.
Data for the mining (NAICS 212) and railroad industries (NAICS 482) are obtained from MSHA and FRA, respectively, and are considered a census. Since these data are obtained from outside sources for which there is no ability to assess reliability, set the variance and covariance estimates for these industries to 0 before summarization for any estimation domain of interest. This means MSHA and FRA strata only contribute to point estimates (total and rate).
Data for mining, railroad, and dummy records will not have sample information available for them. Set the original sample weight to 1 for the following LDB numbers:
LDB number starting with ‘995’: these are dummy records where there were no usable cases across all five size classes within a TEI and FIPS State Code. Proration happens in the benchmarking process for Annual Summary. The system looks for the closest sibling TEI and essentially imputes a number of summary cases from sibling TEIs. The original sample weight shall be set to 1 to be self-representing for LDB numbers starting with ‘995’.
LDB number starting with ‘996’: these are railroad industries (NAICS 482). FRA provides a data set of all injuries and illnesses that happen in the railroad industry. There is no sampling done for this industry. The original sample weight shall be set to 1 for LDB numbers starting with ‘996’.
LDB number starting with ‘997’: these are mining industries (NAICS 212). MSHA provides a data set of all injuries and illnesses that happen in the mining industry. There is no sampling done for this industry. The original sample weight shall be set to 1 for LDB numbers starting with ‘997’.
Variance Estimation: Calculate the variance for totals of case counts (weighted estimates) for each case type (DART, DAFW, DJTR) using the unbiased formula below for weighted samples.
For biennial years, calculate the variance for one collection year at a time and then add the two variances together for the biennial variance.
If the number of Summary usable establishments in the estimation stratum and the number of establishments in the sampling stratum equal 1, then set the variance equal to 0.
If the number of usable establishments in the estimation stratum is greater than 1 and the number of establishments in the sampling stratum is greater than 1, then the variance is calculated by the following:

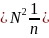

Where:
 is
the total weighted estimate of the variable (case counts for
each collection year, FIPS state code, ownership code, reported
size, case type, characteristic name (e.g., gender_code),
characteristic value (e.g., 2-female), cross characteristic name
(e.g., day_of_week), cross characteristic value (e.g., 3 –
Tuesday)) for all usable establishments in the estimation
stratum:
is
the total weighted estimate of the variable (case counts for
each collection year, FIPS state code, ownership code, reported
size, case type, characteristic name (e.g., gender_code),
characteristic value (e.g., 2-female), cross characteristic name
(e.g., day_of_week), cross characteristic value (e.g., 3 –
Tuesday)) for all usable establishments in the estimation
stratum:
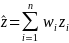 .
For biennial years, wi and zi will be different based on
collection year. See below for more clarification on the
individual variables.
.
For biennial years, wi and zi will be different based on
collection year. See below for more clarification on the
individual variables.
If
is
equal to 0, then the variance, covariance, and RSE for
and
 are equal to 0.
are equal to 0.
N is the sum of Summary final weights for usable establishments in the estimation stratum:
 .
For biennial years, N will be the sum of the Summary
final weights for usable establishments in the individual
collection year. Note: N will be different based on
collection year.
.
For biennial years, N will be the sum of the Summary
final weights for usable establishments in the individual
collection year. Note: N will be different based on
collection year.
n is the number of Summary usable establishments reporting in the estimation stratum. For biennial years, n will be the count of the usable establishments in the individual collection year. Note: n will be different based on collection year.
owi is the Summary original sampling weight of establishment i in the estimation stratum. For biennial years, owi will be the sum of the Summary original sampling weights for all establishments in the individual collection year. Note: owi will be different based on collection year.
wi is the Summary final weight of establishment i in the estimation stratum. For biennial years, wi will be the Summary final weights for usable establishments in the individual collection year. Note: wi will be different based on collection year.
zi is the weighted reported case value of the variable (case counts for each collection year, FIPS state code, ownership code, reported size, case type, characteristic name (e.g., gender_code), characteristic value (e.g., 2-female), cross characteristic name (e.g., day_of_week), cross characteristic value (e.g., 3 – Tuesday)) for establishment i in the estimation stratum
For each establishment, count the number of cases within each collection year, FIPS state code, ownership code, reported size, case type, characteristic name, characteristic value, cross characteristic name, and cross characteristic value for the associated estimate.
If the count is 0, then set zi to 0.
Otherwise, if the count is positive, multiply the count from the previous bullet by the CSSF, CNRAF, and CRAF for the case type for establishment i.
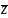 is the weighted average value of the variable (case counts for
each collection year, FIPS state code, ownership code, reported
size, case type, characteristic name (e.g., gender_code),
characteristic value (e.g., 2-female), cross characteristic name
(e.g., day_of_week), cross characteristic value (e.g., 3 –
Tuesday)) for all usable establishments in the estimation
stratum:
is the weighted average value of the variable (case counts for
each collection year, FIPS state code, ownership code, reported
size, case type, characteristic name (e.g., gender_code),
characteristic value (e.g., 2-female), cross characteristic name
(e.g., day_of_week), cross characteristic value (e.g., 3 –
Tuesday)) for all usable establishments in the estimation
stratum:

If the number of usable establishments in the estimation stratum equals 1 and the number of establishments in the sampling stratum is not equal to 1, the mean of the stratum,
 cannot be used because it will yield an incorrect variance of 0.
To correct for this, use the mean from the roll-up hierarchy (TEI
aggregate levels – TEI6, TEI5, TEI4, TEI3, Sector,
Super_Sector, and Domain).
cannot be used because it will yield an incorrect variance of 0.
To correct for this, use the mean from the roll-up hierarchy (TEI
aggregate levels – TEI6, TEI5, TEI4, TEI3, Sector,
Super_Sector, and Domain).The sum of final weights of all usable establishments in the estimation stratum is the frame size for this estimation stratum. Therefore, there would be no missing values for frame size.
That is, if there is only one usable establishment in the estimation stratum and the number of establishments in the sampling stratum is not equal to 1, calculate the variance as the variance of the roll-up level where the mean is the mean of the collection year, FIPS state code, ownership code, reported size class, case type, characteristic, cross characteristic, and parent TEI of the usable establishments in this roll-up level. However, if the one usable establishment in the estimation stratum is also the only usable establishment for the roll-up estimation stratum, continue to roll-up by parent TEI level as far as the industry domain level until the number of usable establishments is greater than 1.
If the one usable establishment in the estimation stratum is also the only usable establishment for the collection year, FIPS state code, ownership code, reported size class, and industry domain, case type, characteristics, and cross characteristics, calculate the variance as the variance of the roll-up level where the mean is the mean of collection year, FIPS state code, ownership code, reported size class 0 (all sizes) and TEI. Continue to roll-up the parent TEI level as far as all industries until the number of usable establishments is greater than 1.
Therefore, if the number of usable establishments in the estimation stratum equals 1 and the number of establishments in the sampling stratum is not equal to 1, we assign the roll-up level variance for this single usable establishment; in other words, we use the roll-up level variance to approximate the variance for this single establishment stratum. The variance is calculated in the same way as those strata with more than one usable establishment; it just includes all usable establishments at the roll-up level. Specifically, the variance for the stratum with single usable establishment is calculated as the following:


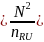
Where:
 is the total weighted estimate of the variable (case counts for
each collection year, FIPS state code, ownership code, reported
size, case type, characteristic name (e.g., gender_code),
characteristic value (e.g., 2-female), cross characteristic name
(e.g., day_of_week), cross characteristic value (e.g., 3 –
Tuesday) for all usable establishments in the roll-up level:
is the total weighted estimate of the variable (case counts for
each collection year, FIPS state code, ownership code, reported
size, case type, characteristic name (e.g., gender_code),
characteristic value (e.g., 2-female), cross characteristic name
(e.g., day_of_week), cross characteristic value (e.g., 3 –
Tuesday) for all usable establishments in the roll-up level:
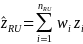 .
For biennial years, wi
and zi will be different based on collection year. See below
for more clarification on the individual variables.
.
For biennial years, wi
and zi will be different based on collection year. See below
for more clarification on the individual variables.N is the sum of Summary final weights for usable establishments in the estimation stratum:
,
in this case it is the single usable establishment estimation
stratum, so N =
 .
For biennial years, N will be different based on
collection year.
.
For biennial years, N will be different based on
collection year.
 is the sum of Summary final weights for usable establishments in
the roll-up level:
is the sum of Summary final weights for usable establishments in
the roll-up level:
 .
For biennial years,
will be different based on collection year.
.
For biennial years,
will be different based on collection year.
 is the number of usable establishments reporting in the roll-up
level. For biennial years,
will be the count of the usable establishments in the individual
collection year. Note:
will be different based on collection year. For example, one
collection year could have more than one usable establishment
and the other collection year have only one usable establishment
meeting this roll-up condition within the same FIPS state code,
ownership code, reported size, case type, characteristic, and
cross characteristic.
is the number of usable establishments reporting in the roll-up
level. For biennial years,
will be the count of the usable establishments in the individual
collection year. Note:
will be different based on collection year. For example, one
collection year could have more than one usable establishment
and the other collection year have only one usable establishment
meeting this roll-up condition within the same FIPS state code,
ownership code, reported size, case type, characteristic, and
cross characteristic.owi is the Summary original sampling weight of establishment i . For biennial years, owi will be the Summary original sampling weights for all establishments in the individual collection year. Note: owi will be different based on collection year. In addition, the owi is the original weight of establishment i at time of sampling, so the TEI used at time of sampling may not be the same TEI used in the roll-up.
wi is the Summary final weight of establishment i in the roll-up level. For biennial years, wi will be the Summary final weights for usable establishments in the individual collection year. Note: wi will be different based on collection year.
zi is the weighted estimate value of the variable (case counts for each collection year, FIPS state code, ownership code, reported size, case type, characteristic name (e.g., gender_code), characteristic value (e.g., 2-female), cross characteristic name (e.g., day_of_week), cross characteristic value (e.g., 3 – Tuesday)) for establishment i in the roll-up level
For each establishment, count the number of cases within each collection year, FIPS state code, ownership code, case type, reported size, characteristic name, characteristic value, cross characteristic name, and cross characteristic value for the associated estimate.
If the count is 0, then set zi to 0.
Otherwise, if the count is positive, zi = the count from the previous bullet * CSSF * CNRAF * CRAF for the case type for establishment i
 is the weighted average value of the variable (case counts for
each collection year, FIPS state code, ownership code, reported
size, case type, characteristic name (e.g., gender_code),
characteristic value (e.g., 2-female), cross characteristic name
(e.g., day_of_week), cross characteristic value (e.g., 3 –
Tuesday)) for all usable establishments in the roll-up level:
is the weighted average value of the variable (case counts for
each collection year, FIPS state code, ownership code, reported
size, case type, characteristic name (e.g., gender_code),
characteristic value (e.g., 2-female), cross characteristic name
(e.g., day_of_week), cross characteristic value (e.g., 3 –
Tuesday)) for all usable establishments in the roll-up level:
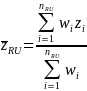
Variance Estimation: Calculate the variance for hours using the unbiased formula below for weighted samples. Note: These requirements for the variance of weighted hours are the same as Annual Summary. To save processing time, obtain the information on the weighted hours (W) and the hours variance (W_Variance) from Annual Summary where reported size is 1-5. This should be brought into the program prior to summing within an estimation cell or across estimation cells for roll-ups.
For biennial years, calculate the variance for one collection year at a time and then add the two variances together for the biennial variance.
If the number of Summary usable establishments in the estimation stratum and the number of establishments in the sampling stratum equal 1, then set the variance equal to 0.
If the number of usable establishments in the estimation stratum is greater than 1 and the number of establishments in the sampling stratum is greater than 1, then the variance is calculated by the following:

Where:
 is
the total weighted hours worked of the variable (hours for each
collection year, FIPS state code, ownership code, reported size,
case type, LDB number)) for all usable establishments in the
estimation stratum:
is
the total weighted hours worked of the variable (hours for each
collection year, FIPS state code, ownership code, reported size,
case type, LDB number)) for all usable establishments in the
estimation stratum:
 .
For biennial years, wtd_hrs_workedi
will be different based on collection year. See below for more
clarification on the individual variable.
.
For biennial years, wtd_hrs_workedi
will be different based on collection year. See below for more
clarification on the individual variable.If there are multiple cases reported for a single LDB number within a given estimation stratum, then only include the weighted hours worked once for the establishment and not for each individual case.
If
is
equal to 0, then the variance and covariance for
are equal to 0.wtd_hrs_workedi is the Summary final weight * total_hrs_worked of establishment i in the estimation stratum.
N is the sum of Summary final weights for usable establishments in the estimation stratum:
.
For biennial years, N will be the sum of the Summary final
weights for usable establishments in the individual collection
year. Note: N will be different based on collection year.
n is the number of Summary usable establishments reporting in the estimation stratum. For biennial years, n will be the count of the usable establishments in the individual collection year. Note: n will be different based on collection year. For example, one collection year could have more than one usable establishment and the other collection year have only one usable establishment meeting this roll-up condition within the same FIPS state code, ownership code, reported size, case type, characteristic, cross characteristic.
owi is the Summary original sampling weight of establishment i in the estimation. For biennial years, owi will be the sum of the Summary original sampling weights for all establishments in the individual collection year. Note: owi will be different based on collection year.
wi is the Summary final weight of establishment i in the estimation stratum. For biennial years, wi will be the Summary final weights for usable establishments in the individual collection year. Note: wi will be different based on collection year.
yi is the reported value of the variable (total hours worked for each collection year, FIPS state code, ownership code, reported size, case type, LDB number) for establishment i in the estimation stratum. For biennial years, yi will be different based on collection year.
 is the weighted average value of the variable (total hours
worked for each collection year, FIPS state code, ownership
code, reported size, case type, LDB number) for all usable
establishments in the estimation stratum:
is the weighted average value of the variable (total hours
worked for each collection year, FIPS state code, ownership
code, reported size, case type, LDB number) for all usable
establishments in the estimation stratum:

If the number of usable establishments in the estimation stratum equals 1 and the number of establishments in the sampling stratum is not equal to 1, the mean of the stratum,
 cannot be used because it will yield an incorrect variance of 0.
To correct for this, use the mean from the roll-up hierarchy.
cannot be used because it will yield an incorrect variance of 0.
To correct for this, use the mean from the roll-up hierarchy.
That is, if there is only one usable establishment in the estimation stratum and the number of establishments in the sampling stratum is not equal to 1, calculate the variance as the variance of the roll-up level where the mean is the mean of the collection year, FIPS state code, ownership code , reported size class, case type, characteristic, cross characteristic, and parent TEI of the usable establishments in this roll-up level. However, if the one usable establishment in the estimation stratum is also the only usable establishment for the roll-up estimation stratum, continue to roll-up by parent TEI level as far as the industry domain level until the number of usable establishments is greater than 1.
If the one usable establishment in the estimation stratum is also the only usable establishment for the collection year, FIPS state code, ownership code, reported size class, and industry domain, case type, characteristics, and cross characteristics, calculate the variance as the variance of the roll-up level where the mean is the mean of collection year, FIPS state code, ownership code, reported size class 0 (all sizes) and TEI. Continue to roll-up the parent TEI level as far as all industries until the number of usable establishments is greater than 1.
Therefore, if the number of usable establishments in the estimation stratum equals 1 and the number of establishments in the sampling stratum is not equal to 1, we assign the roll-up level variance for this single usable establishment; in other words, we use the roll-up level variance to approximate the variance for this single establishment stratum. The variance is calculated in the same way as those strata with more than one usable establishment; it just includes all usable establishments at the roll-up level. Specifically, the variance for the stratum with single usable establishment is calculated as the following:

Where:
 is the total weighted estimate of the variable (hours for each
collection year, FIPS state code, ownership code, reported size,
case type, LDB number) for all usable establishments in the
roll-up level:
is the total weighted estimate of the variable (hours for each
collection year, FIPS state code, ownership code, reported size,
case type, LDB number) for all usable establishments in the
roll-up level:
 .
For biennial years, wtd_hrs_workedi
will be different based on collection year. See below for more
clarification on the individual variable.
.
For biennial years, wtd_hrs_workedi
will be different based on collection year. See below for more
clarification on the individual variable.wtd_hrs_workedi is the Summary final weight * total_hrs_worked of establishment i in the estimation stratum.
N is the sum of Summary final weights for usable establishments in the estimation stratum:
,
in this case it is the single usable establishment estimation
stratum, so N =
.
For biennial years, N will be different based on
collection year.
-
is the sum of Summary final weights for usable establishments in
the roll-up level:
.
For biennial years,
will be different based on collection year.
-
is the number of usable establishments reporting in the roll-up
level. For biennial years,
will be the count of the usable establishments in the individual
collection year. Note:
will be different based on collection year. For example, one
collection year could have more than one usable establishment
and the other collection year have only one usable establishment
meeting this roll-up condition within the same FIPS state code,
ownership code, reported size, case type, characteristic, cross
characteristic.
owi is the Summary original sampling weight of establishment i. For biennial years, owi will be the Summary original sampling weights for all establishments in the individual collection year. Note: owi will be different based on collection year. In addition, the owi is the original weight of establishment i at time of sampling, so the TEI used at time of sampling may not be the same TEI used in the roll-up.
wi is the Summary final weight of establishment i in the roll-up level. For biennial years, wi will be the Summary final weights for usable establishments in the individual collection year. Note: wi will be different based on collection year.
yi is the reported value of the variable (total hours worked for each collection year, FIPS state code, ownership code, reported size, LDB number)) for establishment i in the roll-up level. For biennial years, yi will be different based on collection year.
 is the weighted average value of the variable (total hours
worked for each collection year, FIPS state code, ownership
code, reported size, LDB_number)) for all usable establishments
in the roll-up level:
is the weighted average value of the variable (total hours
worked for each collection year, FIPS state code, ownership
code, reported size, LDB_number)) for all usable establishments
in the roll-up level:

For biennial years, wi and yi will be different based on collection year. See above for more clarification on the individual variables.
Covariance Estimation: Calculate the covariance for total case counts for each collection year, FIPS state code, ownership code, reported size, case type, characteristic name (e.g., gender_code), characteristic value (e.g., 2 - female), cross characteristic name (e.g., day_of_week), cross characteristic value (e.g., 3 - Tuesday) with hours.
If the number of usable establishments in the estimation stratum and the number of establishments in the sampling stratum equal 1, set the covariance equal to 0.
If the number of usable establishments in the estimation stratum is greater than 1 and the number of establishments in the sampling stratum is greater than 1, the covariance is calculated by the following:

Where:
-
is
the total weighted estimate of the variable (case counts for
each collection year, FIPS state code, ownership code, reported
size, case type, characteristic name (e.g., gender_code),
characteristic value (e.g., 2 - female), cross characteristic
name (e.g., day_of_week), cross characteristic value (e.g., 3 -
Tuesday)) for all usable establishments in the estimation
stratum:
.
For biennial years, wi
and zi
will be different based on collection year. See below for
more clarification on the individual variables.
If
is
equal to 0, then the variance, and covariance and RSE for
and
are equal to 0.
-
is
the total weighted estimate of the variable (total hours worked)
for all usable establishments in the estimation stratum:
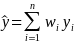 .
For biennial years, wi and yi
will be different based on collection year. See
below for more clarification on the individual variables.
.
For biennial years, wi and yi
will be different based on collection year. See
below for more clarification on the individual variables. N is the sum of Summary final weights for usable establishments in the estimation stratum:
.
For biennial years, N will be the sum of the Summary
final weights for usable establishments in the individual
collection year. Note: N will be different based on
collection year.n is the number of usable establishments reporting in the estimation stratum. For biennial years, n will be the count of the usable establishments in the individual collection year. Note: n will be different based on collection year.
owi is the Summary original sampling weight of establishment i in the estimation stratum. For biennial years, owi will be the sum of the Summary original sampling weights for all establishments in the individual collection year. Note: owi will be different based on collection year.
wi is the Summary final weight of establishment i in the estimation stratum. For biennial years, wi will be the Summary final weights for usable establishments in the individual collection year. Note: wi will be different based on collection year.
zi is the weighted reported value of the variable (case counts for each collection year, FIPS state code, ownership code, reported size, case type, characteristic name (e.g., gender_code), characteristic value (e.g., 2-female), cross characteristic name (e.g., day_of_week), cross characteristic value (e.g., 3 – Tuesday)) for establishment i in the estimation stratum.
For each establishment, count the number of cases within each collection year, FIPS state code, ownership code, case type, reported size, characteristic name, characteristic value, cross characteristic name, and cross characteristic value for the associated estimate.
If the count is 0, then set zi to 0.
Otherwise, if the count is positive, zi = the count from the previous bullet * CSSF * CNRAF * CRAF for the case type for establishment i
-
is the weighted average value of the variable (case counts for
each collection year, FIPS state code, ownership code, reported
size, case type, characteristic name (e.g., gender_code),
characteristic value (e.g., 2-female), cross characteristic name
(e.g., day_of_week), cross characteristic value (e.g., 3 –
Tuesday)) for all usable establishments in the estimation
stratum:
yi is the reported value of the variable (total hours worked for each collection year, FIPS state code, ownership code, reported size, LDB number) for establishment i in the estimation stratum. For biennial years, yi will be different based on collection year.
-
is the weighted average value of the variable (total hours
worked for each collection year, FIPS state code, ownership
code, reported size, LDB number) for all usable establishments
in the estimation stratum:
.
For biennial years, wi
and yi
will be different based on collection year. See
above for more clarification on the individual variables.
If the number of usable establishments equals 1 and the number of stratum sample establishments is not equal to 1, the means,
or
,
cannot be used because they will yield an incorrect covariance of
0. To correct for this, we need to use the means from the roll-up
hierarchy:If there is only one usable establishment in the estimation stratum and the number of establishments in the sampling stratum is not equal to 1, calculate the variance as the variance of the roll-up level where the mean is the mean of the collection year, FIPS state code, ownership code, reported size class, case type, characteristic, cross characteristic, and parent TEI of the usable establishments in this roll-up level. However, if the one usable establishment in the estimation stratum is also the only usable establishment for the roll-up estimation stratum, continue to roll-up by parent TEI level as far as the industry domain level until the number of usable establishments is greater than 1.
If the one usable establishment in the estimation stratum is also the only usable establishment for the collection year, FIPS state code, ownership code, reported size class, and industry domain, case type, characteristics, and cross characteristics, calculate the variance as the variance of the roll-up level where the mean is the mean of collection year, FIPS state code, ownership code, size class 0 (all sizes) and TEI. Continue to roll-up the parent TEI level as far as all industries until the number of usable establishments is greater than 1.
Therefore, where the number of usable establishments in the estimation stratum equals 1 and the number of establishments in the sampling stratum is not equal to 1, similarly we use the roll-up level covariance as the covariance for the single usable establishment stratum. The approximate covariance for the stratum with single usable establishment is calculated by the following:

Where:
-
is
the total weighted estimate of the variable (case counts for
each collection year, FIPS state code, ownership code,
reported size, case type, characteristic name (e.g.,
gender_code), characteristic value (e.g., 2-female), cross
characteristic name (e.g., day_of_week), cross characteristic
value (e.g., 3 – Tuesday)) for all usable
establishments in the roll-up level:
.
For biennial years, wi
and zi
will be different based on collection year. See below
for more clarification on the individual variables.
-
is
the total weighted estimate of the variable (total hours
worked) for all usable establishments in the roll-up level:
 .
For biennial years, wi and yi
will be different based on collection year. See
below for more clarification on the individual variables.
.
For biennial years, wi and yi
will be different based on collection year. See
below for more clarification on the individual variables.
N is the sum of Summary final weights for usable establishments in the estimation stratum:
,
in this case it is the single usable establishment estimation
stratum, so N =
.
For biennial years, N will be different based on
collection year.
-
is the sum of Summary final weights for usable establishments
in the roll-up level:
.
For biennial years,
will be different based on collection year.
-
is the number of usable establishments reporting in the
roll-up level. For biennial years,
will be the count of the usable establishments in the
individual collection year. Note:
will be different based on collection year. For example, one
collection year could have more than one usable establishment
and the other collection year have only one usable
establishment meeting this roll-up condition within the same
FIPS state code, ownership code, reported size, case type,
characteristic, cross characteristic.
owi is the Summary original sampling weight of establishment i. For biennial years, owi will be the Summary original sampling weights for all establishments in the individual collection year. Note: owi will be different based on collection year. In addition, the owi is the original weight of establishment i at time of sampling, so the TEI used at time of sampling may not be the same TEI used in the roll-up.
wi is the Summary final weight of establishment i in the roll-up level. For biennial years, wi will be the Summary final weights for usable establishments in the individual collection year. Note: wi will be different based on collection year.
zi is the reported value of the variable (case counts for each collection year, FIPS state code, ownership code, reported size, case type, characteristic name (e.g., gender_code), characteristic value (e.g., 2-female), cross characteristic name (e.g., day_of_week), cross characteristic value (e.g., 3 – Tuesday)) for establishment i in the roll-up level.
For each establishment, count the number of cases within each collection year, FIPS state code, ownership code, case type, reported size, characteristic name, characteristic value, cross characteristic name, and cross characteristic value for the associated estimate.
If the count is 0, then set zi to 0.
Otherwise, if the count is positive, zi = the count from the previous bullet * CSSF * CNRAF * CRAF for the case type for establishment i
-
is the weighted average value of the variable (case counts
for each collection year, FIPS state code, ownership code,
reported size, case type, characteristic name (e.g.,
gender_code), characteristic value (e.g., 2-female), cross
characteristic name (e.g., day_of_week), cross characteristic
value (e.g., 3 – Tuesday)) for all usable
establishments in the roll-up level:
yi is the reported value of the variable (total hours worked for each collection year, FIPS state code, ownership code, reported size, LDB number) for establishment i in the roll-up level. For biennial years, yi will be different based on collection year.
-
is the weighted average value of the variable (total hours
worked for each collection year, FIPS state code, ownership
code, reported size, LDB number) for all usable
establishments in the roll-up level. For biennial years, wi
and yi
will be different based on collection year. See
above for more clarification on the individual variables.
Variance of Ratios: Calculate the variance of ratios for each incidence rate estimate.
If the number of usable establishments in the estimation stratum and the number of establishments in the sampling stratum equal 1, set the variance equal to 0.
If the number of usable establishments in the estimation stratum is greater than 1 and the number of establishments in the sampling stratum is greater than 1, calculate the variance of the ratio of total case counts for each collection year, FIPS state code, ownership code, reported size, case type, characteristic name (e.g., gender_code), characteristic value (e.g., 2-female), cross characteristic name (e.g., day_of_week), cross characteristic value (e.g., 3 – Tuesday) (z) and hours (y) (
 )
using the following unbiased formula for weighted samples
)
using the following unbiased formula for weighted samples
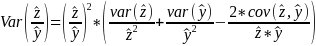
Where:
-
is
the total weighted estimate of the variable (case counts for
each collection year, FIPS state code, ownership code, reported
size, case type, characteristic name (e.g., gender_code),
characteristic value (e.g., 2-female), cross characteristic name
(e.g., day_of_week), cross characteristic value (e.g., 3 –
Tuesday)) for all usable establishments in the estimation
stratum:
.
For biennial years, wi
and zi
will be different based on collection year.
If
is
equal to 0, then the variance, and covariance and RSE for
and
are equal to 0.
wi is the Summary final weight of establishment i in the roll-up level. For biennial years, wi will be the Summary final weights for usable establishments in the individual collection year. Note: wi will be different based on collection year.
zi is the reported value of the variable (case counts for each collection year, FIPS state code, ownership code, reported size, case type, characteristic name (e.g., gender_code), characteristic value (e.g., 2-female), cross characteristic name (e.g., day_of_week), cross characteristic value (e.g., 3 – Tuesday)) for establishment i in the roll-up level.
For each establishment, count the number of cases within each collection year, FIPS state code, ownership code, case type, reported size, characteristic name, characteristic value, cross characteristic name, and cross characteristic value for the associated estimate.
If the count is 0, then set zi to 0.
Otherwise, if the count is positive, zi = the count from the previous bullet * CSSF * CNRAF * CRAF for the case type for establishment i
-
is
the total weighted estimate of the variable (total hours worked)
for all usable establishments in the estimation stratum:
.
For biennial years, wi
and yi
will be different based on collection year.
yi is the reported value of the variable (total hours worked for each collection year, FIPS state code, ownership code, reported size, LDB number) for establishment i in the estimation stratum. For biennial years, yi will be different based on collection year.
 is the variance estimate of the variable in the estimation
stratum (total case counts for each biennial/survey year, FIPS
state code, ownership code, reported size, case type,
characteristic name (e.g., gender_code), characteristic value
(e.g., 2-female), cross characteristic name (e.g., day_of_week),
cross characteristic value (e.g., 3 – Tuesday) (
))
is the variance estimate of the variable in the estimation
stratum (total case counts for each biennial/survey year, FIPS
state code, ownership code, reported size, case type,
characteristic name (e.g., gender_code), characteristic value
(e.g., 2-female), cross characteristic name (e.g., day_of_week),
cross characteristic value (e.g., 3 – Tuesday) (
))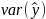 is the variance estimate of the total hours worked in the
estimation stratum total hours worked for each biennial/survey
year, FIPS state code, ownership code, reported size, LDB
number) (
))
is the variance estimate of the total hours worked in the
estimation stratum total hours worked for each biennial/survey
year, FIPS state code, ownership code, reported size, LDB
number) (
)) is the covariance estimate between two variables in the
estimation stratum (case counts of each case type and hours)
is the covariance estimate between two variables in the
estimation stratum (case counts of each case type and hours)
If the incidence rate per 10,000 employees (equivalent 20,000,000
employee hours per year) is reported
 ),
then the variance of incidence rate for case types DART, DAFW,
DJTR is
),
then the variance of incidence rate for case types DART, DAFW,
DJTR is

If the number of usable establishments in the estimation stratum equals 1 and the number of establishments in the sampling stratum is not equal to 1, calculate the variance of the ratio as the variance of total case counts for each case type (
)
and hours (
)
of the roll-up level used above, using the following unbiased
formula for weighted samples

Where:
-
is
the total weighted estimate of the variable (case counts for
each collection year, FIPS state code, ownership code, reported
size, case type, characteristic name (e.g., gender_code),
characteristic value (e.g., 2-female), cross characteristic name
(e.g., day_of_week), cross characteristic value (e.g., 3 –
Tuesday)) for all usable establishments in the estimation
stratum:
.
For biennial years, wi
and zi
will be different based on collection year.
If
is
equal to 0, then the variance, and covariance and RSE for
and
are equal to 0.
wi is the Summary final weight of establishment i in the roll-up level. For biennial years, wi will be the Summary final weights for usable establishments in the individual collection year. Note: wi will be different based on collection year.
zi is the reported value of the variable (case counts for each collection year, FIPS state code, ownership code, reported size, case type, characteristic name (e.g., gender_code), characteristic value (e.g., 2-female), cross characteristic name (e.g., day_of_week), cross characteristic value (e.g., 3 – Tuesday)) for establishment i in the roll-up level.
For each establishment, count the number of cases within each collection year, FIPS state code, ownership code, case type, reported size, characteristic name, characteristic value, cross characteristic name, and cross characteristic value for the associated estimate.
If the count is 0, then set zi to 0.
Otherwise, if the count is positive, zi = the count from the previous bullet * CSSF * CNRAF * CRAF for the case type for establishment i
-
is
the total weighted estimate of the variable (total hours worked)
for all usable establishments in the estimation stratum:
.
For biennial years, wi
and yi
will be different based on collection year.
yi is the reported value of the variable (total hours worked) for establishment i in the estimation stratum. For biennial years, yi will be different based on collection year.
-
is
the total weighted estimate of the variable (case counts for
each collection year, FIPS state code, ownership code, reported
size, case type, characteristic name (e.g., gender_code),
characteristic value (e.g., 2-female), cross characteristic name
(e.g., day_of_week), cross characteristic value (e.g., 3 –
Tuesday)) for all usable establishments in the roll-up level:
-
is
the total weighted estimate of the variable (total hours worked)
for all usable establishments in the roll-up level:
.
For biennial years, wi
and yi
will be different based on collection year. See
below for more clarification on the individual variables.
 is
the variance estimate of the variable (total case counts for
each biennial/survey year, FIPS state code, ownership code,
reported size, case type, characteristic name (e.g.,
gender_code), characteristic value (e.g., 2-female), cross
characteristic name (e.g., day_of_week), cross characteristic
value (e.g., 3 – Tuesday) (
is
the variance estimate of the variable (total case counts for
each biennial/survey year, FIPS state code, ownership code,
reported size, case type, characteristic name (e.g.,
gender_code), characteristic value (e.g., 2-female), cross
characteristic name (e.g., day_of_week), cross characteristic
value (e.g., 3 – Tuesday) (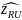 ))
for the roll-up level.
))
for the roll-up level. is the variance estimate of the total hours worked in the
estimation stratum (total hours for each biennial/survey year,
FIPS state code, ownership code, reported size, case type,
characteristic name (e.g., gender_code), characteristic value
(e.g., 2-female), cross characteristic name (e.g., day_of_week),
cross characteristic value (e.g., 3 – Tuesday) (
is the variance estimate of the total hours worked in the
estimation stratum (total hours for each biennial/survey year,
FIPS state code, ownership code, reported size, case type,
characteristic name (e.g., gender_code), characteristic value
(e.g., 2-female), cross characteristic name (e.g., day_of_week),
cross characteristic value (e.g., 3 – Tuesday) (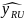 ))
for the roll-up level.
))
for the roll-up level. is
the covariance estimate between two variables (case counts of
each case type and hours) for the roll-up level.
is
the covariance estimate between two variables (case counts of
each case type and hours) for the roll-up level.
If the incidence rate per 10,000 employees (equivalent 20,000,000
employee hours per year) is reported ( ),
then the variance of incidence rate for the roll-up level for
case types DART, DAFW, DJTR is
),
then the variance of incidence rate for the roll-up level for
case types DART, DAFW, DJTR is

Very small variances should be set to zero. Set variances less than the absolute value of 0.000005 to zero.
Percent Relative Standard Error (RSE) Estimation: Calculate the percent relative standard error using the formulas below.
Exclude calculating percent relative standard errors for total hours worked (
).Calculate percent RSE for counts (weighted estimates):
 for totals
for totals
Where:
-
is
the total weighted estimate of the variable (case counts for
each biennial/survey year, FIPS state code, ownership code,
reported size, case type, characteristic name (e.g.,
gender_code), characteristic value (e.g., 2-female), cross
characteristic name (e.g., day_of_week), cross characteristic
value (e.g., 3 – Tuesday)) for all usable establishments
in the stratum. Note that the estimate may be derived from a
single usable establishment or multiple usable establishments.
If
is
equal to 0, then the variance, and covariance and RSE for
and
are equal to 0.
-
is the variance estimate of the variable (case counts for each
biennial/survey year, FIPS state code, ownership code, reported
size, case type, characteristic name (e.g., gender_code),
characteristic value (e.g., 2-female), cross characteristic name
(e.g., day_of_week), cross characteristic value (e.g., 3 –
Tuesday)). Note where the number of usable establishments in the
estimation stratum equals 1 and the number of establishments in
the sampling stratum is not equal to 1, the roll-up level
variance was used to approximate the variance for the single
establishment stratum.
Calculate percent RSE for incidence rates.
Only calculate percent relative standard errors for non-demographic incidence rates. Exclude demographic rates on age group, gender, SOC, and SOC groups.
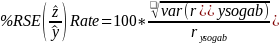 for rates
for rates
Where:
-
is
the total estimate of the variable (total case counts for each
biennial/survey year, FIPS state code, ownership code, reported
size, case type, characteristic name (e.g., gender_code),
characteristic value (e.g., 2-female), cross characteristic
name (e.g., day_of_week), cross characteristic value (e.g., 3 –
Tuesday)) for all usable establishments in the estimation
stratum
-
is
the total estimate of the variable (total hours worked) for all
usable establishments in the estimation stratum
 is
the variance estimate of the incidence rate. Note where the
number of usable establishments in the estimation stratum
equals 1 and the number of establishments in the sampling
stratum is not equal to 1, the roll-up level variance of the
ratio was used to approximate the variance of the ratio for the
single establishment stratum.
is
the variance estimate of the incidence rate. Note where the
number of usable establishments in the estimation stratum
equals 1 and the number of establishments in the sampling
stratum is not equal to 1, the roll-up level variance of the
ratio was used to approximate the variance of the ratio for the
single establishment stratum. is the incidence rate of case counts to hours depending on
which case type is being used.
is the incidence rate of case counts to hours depending on
which case type is being used.
Outputs
SAS dataset
All SAS datasets shall be saved for all successful process IDs
Estimates shall be stored at their full accuracy in a database table.
CD_estimates table – store the following variables associated with their weighted estimate and/or incidence rate.
Variance_counts
Variance_hours
Variance_rates
Covariance_counts_hours
RSE_counts
RSE_rates
Only the most recent successful run of Estimates shall be stored to the database table.
Error checking
Check all counts (weighted estimates) have a variance_counts and RSE_counts. That is variance_counts and RSE_counts are non-missing.
RSE_rates should not be calculated for demographic incidence rates.
APPENDIX A: SOII variance estimation roll-up algorithm
When a detailed SOII stratum, defined by collection year, FIPS state code, ownership code, TEI, and reported employment size, case type, characteristic, and cross characteristic has a single usable establishment, a rolling-up procedure is needed to form a more aggregated stratum with at least two usable establishments to calculate the variance and covariance estimates and assign them for this single-unit stratum. This approach uses the variance estimates for the aggregated stratum to approximate the true variances for this single-unit detailed stratum.
The specific conditions for a stratum rolling-up would be: a stratum has a single establishment with a sampling frame size not equal to one (defined by original weight or final weight) and from industries other than MSHA (mining – NAICS 212) and FRA (railroads – NAICS 482).
The rolling-up procedure involves two main stratum combination or merging to form an aggregated stratum for estimating variance and covariance for SOII outcomes:
Rolling-up within TEI with strata from the same reported employment size group
Rolling-up within TEI with strata from all five reported employment size groups
With the guidance from subject experts, the rolling-up should start with within TEI with strata of the same reported employment size and, if this does not work, then consider within TEI with strata from all reported employment size groups. The rest of this document will first explain the SOII stratum TEI hierarchy and then provide the details on the rolling-up procedure for single-unit stratum variance and covariance estimation.
SOII stratum TEI hierarchy
The SOII stratum TEI hierarchy has seven level structure, from the most detailed level (TEI6: 6-digit NAICS) to the most aggregated level (Domain: equivalent to the combinations of 2-digit NAICS)
TEI6 (6-digit NAICS)
TEI5 (5-digit NAICS)
TEI4 (4-digit NAICS)
TEI3 (3-digit NAICS),
Sector (two-digit NAICS or combinations of two-digit NAICS),
Super-Sector (more aggregated combinations of two-digit NAICS)
Domain (two types of combinations of two-digit NAICS: GP1AAA and SP1AAA)
A TEI for a SOII stratum could be of any level above except Domain that has only two categories: GP1AAA and SP1AAA (see examples in Table 1).
Table 1. Examples of SOII stratum TEI
-
SOII stratum TEI
TEI Hierarchy Level
111411
TEI6
111410
TEI5
111400
TEI4
111000
TEI3
GP2AFH
Sector
GP1NRM
Super Sector
GP1AAA
Domain
I. Rolling-up within TEI with strata from the same employment size group
Step one: a single establishment stratum with TEI will merge with other detailed strata along the TEI hierarchy structure (from TEI5 to Domain) to form a more aggregated stratum until this aggregated stratum has two or more usable establishments. All these detailed strata for aggregation have the same collection year, FIPS state code, and ownership code and belong to the same reported employment size group, case type, characteristic, cross characteristic. The starting aggregation level of TEI depends on the original stratum TEI. If the stratum TEI is TEI6, then the starting aggregation level of TEI would be TEI5; if the stratum TEI is a super-sector, then the starting aggregation level of TEI would be Domain.
Step two: variance and covariance estimates will be calculated for the aggregated stratum and then assigned to the original single establishment stratum with TEI.
If the rolling-up within TEI with strata from the same reported employment size group could not form an aggregated stratum with two or more usable establishments, the rolling-up within TEI with strata from all five reported employment size groups will be applied.
II. Rolling-up within TEI with strata from all five reported employment size groups
Step one: a single establishment stratum with TEI will merge with all other strata having the same TEI from different reported employment size groups to form a more aggregated stratum until this aggregated stratum has two or more usable establishments. All these detailed strata for aggregation have the same collection year, FIPS state code, and ownership code.
Step two: if step one could not form an aggregated strata with two or more usable establishments, then repeat step one but at a more aggregated hierarchy TEI level (from TEI5 to Domain) until the aggregated stratum has at least two usable establishments.
Step three: variance and covariance estimates will be calculated for the aggregated stratum and then assigned to the original single establishment stratum with TEI.
It is rare but it is possible that the above two main rolling-ups could not produce an aggregated stratum with two or more usable establishments. If this is the case, then all the strata that have the same collection year, FIPS state code, and ownership code as the single-unit detailed stratum will be used to form a most aggregated strata to calculate the variance and covariance estimates.
| File Type | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
| Author | Suh, Daniel - BLS CTR |
| File Modified | 0000-00-00 |
| File Created | 2024-07-24 |
© 2026 OMB.report | Privacy Policy