SSB_Persistent Poverty
SSB_Persistent Poverty.docx
Understanding the Relationship Between Poverty, Well-Being, and Food Security
OMB: 0584-0682
Supporting Statement – PART B Justification for OMB Clearance
OMB Supporting Statement 0584-0682
Paperwork Reduction Act of 1995
Understanding the Relationship Between Poverty, Well-Being, and Food Security
Project Officer: Michael Burke
Senior Social Science Research Analyst
USDA, Food and Nutrition Service
March 2024
Office of Policy Support
Food and Nutrition Service
United States Department of Agriculture
1320 Braddock Place
Alexandria, Virginia 22314
Phone: (703) 305-4369
Email: michael.burke@usda.gov
Table of Contents
B.1 Respondent Universe and Sampling Methods 3
B.2 Procedures for the Collection of Information 4
B.3 Methods to Maximize Response Rates and to Deal With Issues of Nonresponse 15
B.4 Test of Procedures or Methods to be Undertaken 18
Tables
B-2.1. Sample sizes and precision for a county with persistent poverty 13
B-2.2. Breakdown of block groups and blocks by county with population and housing unit totals 13
B-5.1. Individuals consulted on data collection or analysis 20
B.1 Respondent Universe and Sampling Methods
Describe (including a numerical estimate) the potential respondent universe and any sampling or other respondent selection method to be used. Data on the number of entities (e.g., establishments, State and local government units, households, or persons) in the universe covered by the collection and in the corresponding sample are to be provided in tabular form for the universe as a whole and for each of the strata in the proposed sample. Indicate expected response rates for the collection as a whole. If the collection had been conducted previously, include the actual response rate achieved during the last collection.
Respondent Universe
The target population (the “universe”) includes all households located in six persistent poverty counties, as of the date of frame construction. Final study counties include: Dougherty County, GA; Estill County, KY; Bolivar County, MS; Ouachita Parish, LA; Dona Ana County, NM; and Dallas County, AL. The populations of most interest include SNAP households (with at least one SNAP unit) and SNAP-eligible nonparticipating households, though all SNAP-ineligible households are also eligible for sampling. SNAP-eligible and near-eligible income thresholds vary by state, but for many states SNAP eligible households will have income below 130 percent of the Federal Poverty Level (FPL) and near-eligibles will have income of 130 to 200 percent of the FPL.
Sampling Methods
We will select an Address-Based Sample (ABS), the industry standard for statistically representative population-based surveys, to survey a representative probability sample of households with residences in each of the six persistent poverty counties (each located within six different states).
The sample design within each county will be a two-stage ABS sample, in which the primary sampling units (PSUs) will be small geographic clusters consisting of census-defined blocks or groups of blocks and the secondary sampling units will be residential addresses within the selected PSUs. We chose this design because we are seeking information (mostly) on SNAP participating households and SNAP-eligible nonparticipating households, two populations that we believe will be clustered in relatively small clusters, and we wanted to use the measure of size (MOS) to control which clusters we select. (The MOS, defined in detail in Section B.2, is an index that indicates the likelihood that the household is SNAP-eligible.) FNS’s administrative data on SNAP participating households indicate that this population tends to be geographically clustered in relatively small clusters. We expect SNAP-eligible nonparticipating households will be clustered in a similar way, based on information known about demographic characteristics that are correlated with eligible nonparticipation (elderly households, noncitizens, or having income exceeding 100 percent of the FPL but still SNAP eligible). We also wanted the capacity for efficient field follow-up. Finally, we wanted to filter out unpopulated areas.
B.2 Procedures for the Collection of Information
Describe the procedures for the collection of information including:
Statistical methodology for stratification and sample selection,
Degree of accuracy needed for the purpose described in the justification,
Unusual problems requiring specialized sampling procedures, and
Any use of periodic (less frequent than annual) data collection cycles to reduce burden.
B.2.1 Statistical Methodology for Stratification and Sample Selection
Household Survey Method
As stated earlier, we want to select PSUs (census blocks or groups of census blocks) that are more likely to contain the two populations that we are most interested in: SNAP participating households and SNAP-eligible nonparticipating households. (Note that the second stage of selection is addresses, which will contain one or more households.) However, we only have good data on the SNAP participating households. Therefore, we will begin by obtaining all addresses in the selected counties using the U.S. Postal Service’s Delivery Sequence File (DSF) from the most recent month (from Marketing Systems Group, Inc. [MSG] and its GENESYS system) and match them with addresses identifying SNAP households in SNAP administrative data for each of the six counties. We will then assign an index to each PSU that reflects the likelihood that the PSU contains SNAP participating households, and adjust that index using variables in the American Community Survey (ACS) data that are known to be correlated with SNAP eligibility (elderly households, noncitizens, or having income exceeding 100 percent of the FPL but still SNAP eligible) to increase the likelihood that we sample SNAP-eligible nonparticipating households. This index will have larger values for PSUs with more of these types of households, and we will select the PSUs with probability proportional to this index. Using this index as an MOS will hopefully ensure that PSUs with higher concentrations of SNAP participants and estimated SNAP-eligible nonparticipants are selected. However, all PSUs have some chance of selection, enabling the full sample to be representative of the overall county.
After selecting the PSUs, we will select samples of addresses in the second sampling stage from the list of addresses obtained from the DSF, but limited to those located within the selected PSUs. We will stratify the addresses within the selected PSUs into two strata according to SNAP participation (SNAP participant versus non-participant) using SNAP administrative data, and we will allocate the sample accordingly by selecting predetermined numbers of SNAP households in each PSU. Addresses will be randomly selected within each stratum, using systematic sampling. This will ensure we obtain sufficiently large numbers of SNAP households in our sample. The exact number of addresses that will be released for initial data collection will be determined once we have defined PSUs from blocks and will be based on anticipated completion rates. We will select more addresses than needed to ensure we have enough sample cases to meet our targeted number of completed interviews, in case the actual completion rates do not meet expectations.
After having stratified the addresses within the selected PSUs according to SNAP status, we will still have to ensure the selected sample will have enough SNAP-eligible nonparticipating households. Because we will not have household-level income information for the full sample frame, we will not know with certainty which non-SNAP households are SNAP eligible and which are not within the sampled PSUs. This implies we cannot stratify based on SNAP eligibility and thus cannot select a predetermined number of SNAP-eligible nonparticipating households. However, we believe the described approach of selecting PSUs based on their likelihood of having SNAP-eligible nonparticipating households will lead to a final sample that enables us to reach our target number of these SNAP-eligible non-participating households.
The study will be designed to reach a precision level of plus or minus 5 percentage points around point estimates in each county for (1) all sampled households, (2) the SNAP participating households subsample, and (3) the SNAP-eligible nonparticipating households subsample.1 To meet these targets, we considered the sample design described above and conducted a power analysis to determine the required sample sizes. Because the precision of estimates varies based on the value of the outcome, we present estimates for an outcome equal to 20 and 50 percent, and we made a set of assumptions about the underlying population distribution of low-income and SNAP participant households.
In-Depth Interview Sampling Method
In-depth Interview (IDI) participants will be drawn from survey respondents. At the end of the survey, respondents will be asked if they are willing to participate in an IDI. For each county, we will review responses to the survey to identify multigenerational households among the SNAP and SNAP-eligible respondents who expressed interest in being contacted again. Specifically, this will enable us to identify multigenerational households that contain multiple adult generations within the same household. This will form the IDI sampling frame from which households will be randomly selected. Each household participating in IDIs is expected to yield two individual interviews (each a different generation), for a total of 24-26 individual interviews per county.
After identifying multigenerational households that completed a survey and indicated willingness to participate in the IDIs, we will create four sampling strata by crossing two binary characteristics: (1) SNAP participant or not and (2) food insecure or not. We will select a sample of 12 households per county, roughly divided among the four strata. We will attempt to account for other characteristics, such as by very low food security status (within the food-insecure strata) or by whether the household resides in a hard-to-reach community to ensure sufficient representation from these households. We will also oversample Spanish speakers (especially in the county with a high proportion of Spanish speakers) as much as possible.
Trained recruiters will contact the respondents in the IDI sample frame and follow an invitation call script that asks: 1) if they are willing to participate in an IDI and, 2) if there is an adult family member from a different generation living in the household who would also be willing to be interviewed. If the response is affirmative on both counts, the recruiter will schedule interviews for both respondents. If only the initial contact is willing and available to participate in the IDI, the recruiter will inquire whether a relative or family member from a different generation residing in the same county could participate and will contact them to confirm their relationship with the IDI respondent identified through the survey and invite them to participate in the IDI. After scheduling the interviews, each adult family member will be sent a confirmation letter or email, if preferred (Appendix M1/M2. IDI Confirmation Letter/Email) and receive a reminder call a few days before the appointment (Appendix N1/N2. IDI Reminder Call Script).
B.2.2 Estimation Procedures
The analysis of survey data from such a complex sample design requires the use of weights to compensate for various probabilities of selection and special methods to compute standard errors. From the inverse of the selection probability, we compute the base weight associated with a sampled household to account for the fact that some households in the county are more likely to be represented in the sample than others. The probability of selection is the product of the selection probability at each sampling stage-the PSU (as needed), and the household. Therefore, the initial sampling weight will be the inverse of the full selection probability for each case. The following component probabilities are the basis to calculate the probability of selection:
1. The probability of selecting PSU i within PSU stratum h, hi, is hi = 1 for certainty PSUs; for noncertainty PSUs, the selection probability is given by
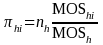 ,
,
where nh is the sample size for stratum h. .
2. If secondary units are selected within the hi-th PSU, the probability of selecting secondary unit j is given by
![]() .
.
where
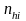 is
the sample size for secondary units in PSU hi,
is
the sample size for secondary units in PSU hi,
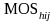 is
the measure of size of the secondary unit, and
is
the measure of size of the secondary unit, and
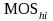 is the total measure of size for all secondary units in PSU hi.
is the total measure of size for all secondary units in PSU hi.
3. We are only planning two stages of selection, with a sample of groups of blocks, and addresses within those groups of blocks. However, if this changes and we feel that subareas are required, then the probability of selecting a given household within stratum s of secondary unit j in the hi-th PSU is given by
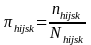 ,
,
where nhijsk and Nhijsk are the sample and population size, respectively, for the hijsk-th stratum within secondary unit j of PSU hi, assuming subareas are used. When subareas are not used, j drops out of the subscripts.
Finally, the overall selection probability is given by the following:
Overall
selection probability =
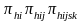 .
.
The initial sampling weight is calculated as
Base
weight =
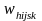 =
=
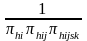 .
.
The subscript j is dropped from the last two formulas for PSUs in which subareas are not sampled.
The use of base weights will yield unbiased estimates if there is adequate coverage and no survey nonresponse. Unit nonresponse (that is, whole questionnaire nonresponse) occurs when an eligible sampled household fails to respond to the survey. We will adjust the base weights with propensity scores to reduce the potential for bias due to unit nonresponse, created using logistic regression models. We will do this using two adjustments: one for eligibility determination (known versus unknown eligibility) and cooperation amongst those with known eligibility. Covariates in these models are variables available for both respondents and nonrespondents and are chosen because of their relation to the likelihood of poor survey response and an assumed relationship to the data outcomes. At a minimum, candidates for covariates used in the models will include the strata used in sampling. It is important that each level of the model covariates has enough sample members to ensure a stable adjustment. We will develop the models using data available for all sample members, which may require separate adjustments for SNAP households, SNAP-eligible nonparticipants, and SNAP-ineligible households. The eligibility determination and response logistic models provide estimated propensity scores for each respondent accounting for individuals with similar characteristics who we cannot locate or who did not respond. We will evaluate whether to use the inverse of the propensity score directly as the adjustment factor, or to calculate the adjustment factor using weighting cells based on the propensity scores. The adjusted weight for each sample case will be the product of the initial sampling weight and the adjustment factor.
We view propensity modeling as the extension of the standard weighting class procedure. We will use propensity modeling instead of the standard weighting class procedure because it allows us to use more factors and complex interactions among factors to explain the differential propensity located or to respond. In addition, we will use available standard statistical tests to evaluate the selection of variables for the model. To identify the factors for inclusion in the models, we will use bivariate cross-tabulations and multivariate procedures, such as interaction detection procedures (for example, Chi-squared Automatic Interaction Detection, or CHAID, software). To evaluate the candidate factors and interactions, we will use a weighted stepwise procedure. We will then check the final model using survey data analysis software to obtain design-based precision estimates for assessing the final set of factors. We expect to require separate models for some survey populations because different populations have different amounts of information available (for example, we will have more information on SNAP participant households than on non-participants).
After adjusting for nonresponse, we will further adjust the weights so that some weighted sample statistics match known population values, using the raking method for post-stratification. For example, if the weight sum of SNAP households in our sample does not correspond to the total number of SNAP households in the county, we will adjust the weights in a proportional fashion, so the weighted sample and population values correspond.
Variability in sampling weights can severely affect standard errors, particularly in the extreme case where one observation has a sampling weight that is substantially larger than others. We will use “weight trimming” to alleviate this problem. In this procedure, the value of very large weights is simply reduced, with the amount “trimmed” being distributed among other sample members in some way. Reducing the weight can create biased estimates, but when one or two individuals have extremely large weights, the contribution to variance reduction outweighs the bias that might be created by trimming.
One way to protect against bias is to redistribute the “trimmed” amount over a group of individuals who share some common characteristic with those whose weights were trimmed. We will define these “trimming classes” using variables selected in the same manner we use to select variables for the nonresponse adjustments. Because we will use propensity modeling instead of weighting classes to make the nonresponse adjustments, we will define trimming classes using the most important variables in the propensity models.
For this study, the sampling variance estimate is a function of the sample design and the population parameter we are estimating; this is the design-based sampling variance. The design-based variance assumes the use of “fully adjusted” sampling weights, which derive from the sample design with adjustments to compensate for locating a person; individual nonresponse; and ratio-adjusting the sampling totals to external totals. We will develop a single fully adjusted sampling weight and information on analysis parameters (that is, analysis stratification and analysis clusters) necessary to estimate the sampling variance for a statistic, using the Taylor series linearization approach.
The Taylor series procedure is an appropriate sampling variance estimation technique for complex sample designs. The Taylor series procedure is based on a classic statistical method in which one can approximate a nonlinear statistic by a linear combination of the components within the statistic. The accuracy of the approximation is dependent on the sample size and the complexity of the statistic. For most commonly used nonlinear statistics (such as ratios, means, proportions, and regression coefficients), the linearized form is already developed and has good statistical properties. Once a linearized form of an estimate is developed, one can use the explicit equations for linear estimates to estimate the sampling variance. Because one can use the explicit equations, one can estimate the sampling variance using many features of the sampling design (for example, finite population corrections; stratification; multiple stages of selection; and unequal selection rates within strata). This is the basic variance estimation procedure used in SUDAAN, the survey procedures in SAS, STATA, and other software packages to accommodate simple and complex sampling designs. To calculate variance, we will need sample design information (such as PSU, stratum, and analysis weight) for each sample unit.
B.2.3 Degree of Accuracy Needed
To meet the precision targets for this study, we will sample 220 PSUs per county and complete surveys with an average of 5 households per PSU, for a total of about 1,100 households per county. This includes about 440 SNAP households, 440 SNAP-eligible households, 110 near-eligible households, and 110 SNAP-ineligible households, for a total sample of 1,100 household completes. Such a sample will produce a margin of error of 5 percentage points for an outcome with a mean of 50 percent in the population and a margin of error of 4 percentage points for an outcome with a mean of 20 percent. Although excluded from these precision requirements, estimates for the near-eligible households will have a margin of error of 9.7 percentage points for each county.
To allow for multiple sample releases after necessary refinements, we will select three times the number of addresses that we will target for completed interviews; not all will necessarily be released into the fielded sample.
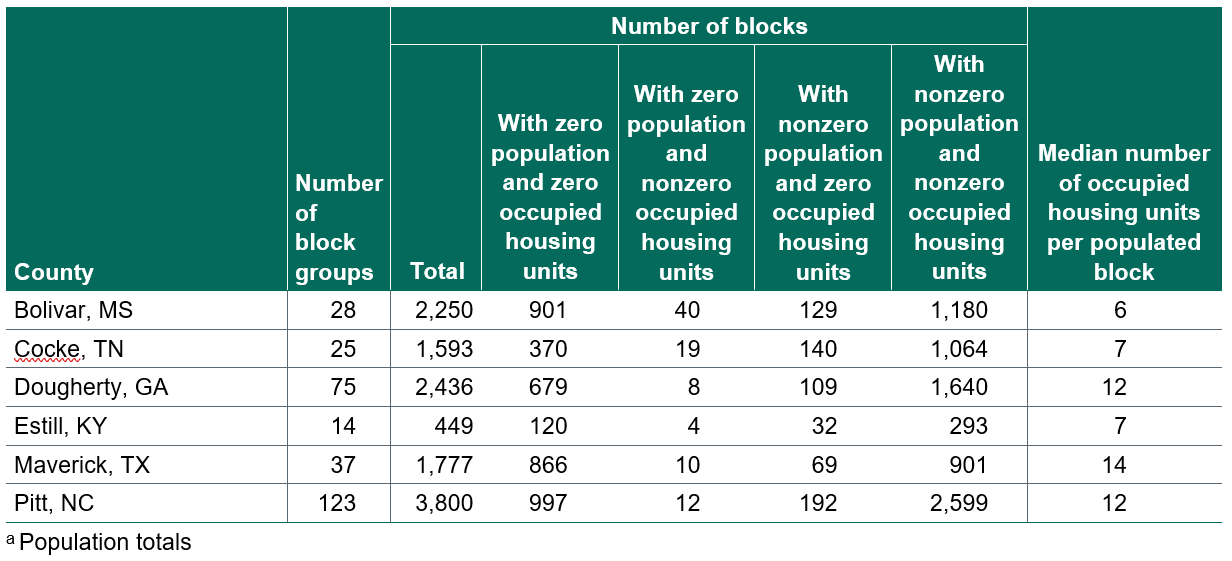
As shown in Table B-2.1, we will need to initially select 3,300 addresses from the 220 PSUs in each county, for an average of 15 addresses per PSU. From Table B-2.2, we see that in Estill County, Kentucky, there are only 293 blocks available for creating the frame of PSUs. This county may end up with fewer than 220 PSUs in the sample, in which case a larger number of households per PSU than other counties would need to be selected to make up for the shortfall. Alternatively, we may be able to apply a finite population correction factor that affects the standard error calculations, making a larger sample of households unnecessary within each PSU. If we cannot obtain 3,300 addresses in a county (such as Estill County, in example list below) we will work with FNS to evaluate whether we need to select more addresses from other counties.
Table B-2.1. Sample sizes and precision for a county with persistent poverty
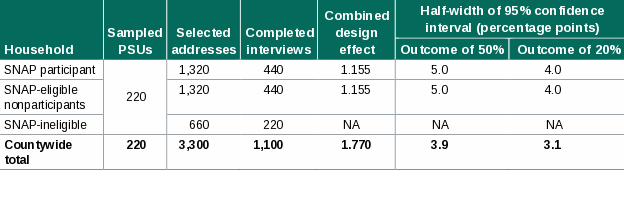
Table B-2.2. Breakdown of block groups and blocks by county with population and housing unit totalsa
B.2.4 Unusual Problems Requiring Specialized Sampling Procedures
As a further step to ensure our targeted number of completed interviews among SNAP participant households, SNAP-eligible nonparticipant households, and SNAP-ineligible households, we will use a staged approach to releasing sampled households with a contingency plan to mitigate against the risk that our initial approach results in too few SNAP-eligible nonparticipating households. In particular, we will select a large initial reserve of PSUs but release randomly selected PSUs into the final sample in stages. The first sample release will include about one-third of the overall sample. Based on responses to questions about SNAP participation, household size, and income, we will evaluate in real time how many SNAP participating and SNAP-eligible nonparticipating households have completed the survey. In addition, we will track how many near-eligible households have completed the survey. If the initial group of survey completers includes too few SNAP-eligible households, we will change the screener and add broad category income questions for households in the second and third sample releases to identify households not eligible for SNAP and screen out such households (when we have reached our target sample size of these households). We will continue releasing samples until we hit our sample size target for each study group.
B.3 Methods to Maximize Response Rates and to Deal With Issues of Nonresponse
Describe methods to maximize response rates and to deal with issues of non-response. The accuracy and reliability of information collected must be shown to be adequate for intended uses. For collections based on sampling, a special justification must be provided for any collection that will not yield “reliable” data that can be generalized to the universe studied.
The study team will employ a variety of methods to maximize response rates and deal with nonresponse. This section describes these methods for the participant survey and for qualitative data collection efforts.
B.3.1 Methods to Maximize Response Rates
Household Survey
The survey will use a sequential multi-mode data collection approach, to obtain the highest possible response rates while minimizing data collection costs. We will start by sending an invitation letter to all sampled addresses with a $5 prepaid cash incentive and brochure with information about the study, asking them to complete the web survey. The letter will include a toll-free number to call to ask question about the study, to receive assistance with accessing the web survey, or to complete the interview over the phone. The advance letter will include a QR code and URL (either will bring respondents to the web-based survey), to give participants several options to participate.
For sample members who do not start the survey but for whom we have a valid phone number, a telephone interviewer will call the household one week after sending the advance letter. If a phone number is not available for the sampled address, or we reach our call attempt thresholds, we will send a field locator in person to the sampled address approximately 8 weeks after the mailing of the advanced letter. If the respondent is willing to participate, the field locator will dial in to the survey center with a cell phone, and a phone interviewer will conduct the survey.2
If a potential respondent does not have time to complete the interview, we will schedule a call-back or a return visit and provide the web log-in information. After initial contact, we will make six additional call attempts before sending a field locator to the residence to complete the interview. The web survey will collect email addresses and phone numbers. We will use this information to follow up with respondents who start but do not complete the web survey.
In-Depth Interviews
The study team will conduct interviews with adult members in 12-13 multigenerational households for a total 24-26 IDIs with adult individuals/households in each study County. The participant interview data will be based on the perceptions of individuals about their life experiences but will not be representative in a statistical sense, in that they are not generalizable and will not be used to make statements about the prevalence of experiences for all individuals/households.
Although the IDI sample will consist of only those who expressed interest in being included in this component of the study, not all sampled households who complete the survey will agree to participate in an IDI. We will select more households than are needed and release backups in random order as needed to achieve the target numbers.
Recruiters will schedule interviews at times convenient to respondents, including daytime and evening (Appendix L1/L2. IDI Invitation Call Script). The interviews will be held in a location convenient to respondents. Should in person interviews not be feasible, for example due to the evolving nature of the current COVID-19 pandemic and associated restrictions, the study team will be prepared to conduct IDIs by phone or video-conferencing if needed.
In recognition that some scheduled interviews may not occur due to cancellations and no-shows, the study team will overschedule the number of appointments needed to reach the target interview goal of 24-26 interviews per County and attempt to reschedule interviews while on-site. The study team will be flexible in scheduling interviews to accommodate participants’ schedules and needs. Respondents will receive a reminder call 24–48 hours before the scheduled appointment (Appendix N1/N2 IDI Reminder Call Script). Those who participate in the in-depth interviews will receive a $50 gift card at the end of the 2-hour interview. Previous studies have demonstrated that providing incentives helps increase response rates in full-scale data collection effort, reduce non-response bias, and improve population representativeness.3, 4
B.3.2 Nonresponse Bias Analysis
We will aim for a response rate of 80 percent, but it is unlikely that we can reach that goal. If our response rates are below 80 percent, we will follow OMB guidelines and run a nonresponse bias analysis that compares differences in PSU- and household-level characteristics between respondents and nonrespondents, and then assesses whether the weights appear to have sufficiently mitigated any risk for nonresponse bias. For SNAP households we can use SNAP administrative data to assist in our assessment for bias. In addition to assessments and remediation of potential bias due to unit nonresponse, we plan to perform statistical imputation for missing values of several variables related to income and SNAP eligibility. We will assess whether the item nonresponse rates are too low for the item in question to be deemed usable by examining whether the item response rate is less than 50 percent and imputation is not feasible.
B.4 Test of Procedures or Methods to be Undertaken
Describe any tests of procedures or methods to be undertaken. Testing is encouraged as an effective means of refining collections of information to minimize burden and improve utility. Tests must be approved if they call for answers to identical questions from 10 or more respondents. A proposed test or set of tests may be submitted for approval separately or in combination with the main collection of information.
The study team conducted a pretest of the survey instrument and a pretest of the IDI instrument. Nine respondents participated in each pretest. These respondents included SNAP beneficiaries, low-income non-SNAP beneficiaries, English speakers, and Spanish speakers in order to assure the pretest reached an audience that is similar to the intended sample. We timed pretest administrations to assess the length of each section the instruments, and included probes to explore the respondent’s understanding of items. We revised the draft instruments following the pretest and based on feedback from pretest participants, we revised the survey to reduce length, simplify the household rostering and incomes sections, and clarified questions and response options.
B.5 Individuals Consulted on Statistical Methods and Individuals Responsible for Collecting and/or Analyzing the Data
Provide the name and telephone number of individuals consulted on statistical aspects of the design and the name of the agency unit, contractor(s), grantee(s), or other person(s) who will actually collect and/or analyze the information for the agency.
Table B-5.1 summarizes the individuals consulted on statistical aspects of the design. Mathematica staff will be responsible for the collection and analysis of the study’s data, in coordination with FNS.
Table B-5.1. Individuals consulted on data collection or analysis
Mathematica Staff |
Title |
Phone |
Andy Weiss |
Project Director |
(734) 794-8025 |
James Mabli |
Co-Principal Investigator |
(617) 301-8997 |
Pamela Holcomb |
Co-Principal Investigator |
(202) 250-3573 |
Leah Shiferaw |
Researcher |
(510) 285-4686 |
Kim McDonald |
Survey Director |
(312) 585-3311 |
Nancy Clusen |
Principal Statistician |
(202) 484-5263 |
Eric Grau |
Senior Statistician |
(609) 945-3330 |
|
|
|
USDA Staff |
Title |
Phone |
Michael Burke, FNS |
Social Science Research Analyst |
(703) 305-4369 |
Kathryn Law, FNS |
Director, SNAP Research and Analysis Division |
(703) 305-2138 |
Anna Vaudin, FNS |
Social Science Research Analyst |
(703) 305-0414 |
Jeffery Hunt |
NASS, Mathematical Statistician |
(202) 720-5539 |
Advisors |
Title |
Phone |
Nicholas Younginer, University of South Carolina |
Research Assistant Professor, Arnold School of Public Health |
(803) 777-4453 |
Alisú Schoua-Glusberg, Research Support Services Inc. |
Principal Research Methodologist |
(847) 864-5677 |
Judi Bartfeld, University of Wisconsin-Madison |
Professor, Department of Consumer Science & Affiliate, Institute for Research on Poverty |
(608) 262-4765 |
Luke Shaefer, University of Michigan |
Professor, Gerald R. Ford School of Public Policy & Director, Poverty Solutions |
(734) 936-5065 |
John Czajka, Formally Mathematica |
Retired Senior Fellow |
(202) 484-4685 |
1 Throughout this section, we refer to “SNAP participant households” and “SNAP-eligible nonparticipant households,” although in practice, there may be some fuzziness with these definitions. FNS defines SNAP participation in terms of SNAP units, which includes a group of people who share their meals with each other. If there is more than one SNAP unit in the household, we will choose one of the SNAP units and it will represent the other one in the household. If not all units in the households are participating in SNAP, we will choose the participating SNAP unit and it will represent the entire household. We will work with FNS to parse out the details of handling households with multiple SNAP units.
2 We will provide field staff with cell phones for respondents to use to complete the survey. Because the study is likely to be in some remote rural areas, we will verify cell phone coverage in advance and use different carriers in different areas if needed. If there is no cell phone coverage at an address, we will ask the respondent to use a landline or schedule an appointment to meet the respondent at a pre-identified public place where cell coverage is available.
3 Singer, E., and R.A. Kulka. “Paying Respondents for Survey Participation.” In Studies of Welfare Populations: Data Collection and Research Issues. Panel on Data and Methods for Measuring the Effects of Changes in Social Welfare Programs, edited by Michele Ver Ploeg, Robert A. Moffitt, and Constance F. Citro. Committee on National Statistics, Division of Behavioral and Social Sciences and Education. Washington, DC: National Academy Press, 2002, pp. 105–128.
4 Singer, E., and C. Ye. “The Use and Effects of Incentives in Surveys.” The Annals of the American Academy of Political and Social Science, 2013, vol. 645, no. 112.
| File Type | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
| Author | Danielle Jacobs |
| File Modified | 0000-00-00 |
| File Created | 2024-07-20 |
© 2026 OMB.report | Privacy Policy