APEC IV OMB Part B_5.16.22_clean
APEC IV OMB Part B_5.16.22_clean.docx
Fourth Access, Participation, Eligibility, and Certification Study Series (APEC IV)
OMB: 0584-0530
Supporting Statement – Part B
for
OMB Control Number 0584-0530
Fourth Access, Participation, Eligibility, and Certification Study (APEC IV)
February 2022
Project Officer: Amy Rosenthal
Office of Policy Support
Food and Nutrition Service
United States Department of Agriculture
1320 Braddock Place
Alexandria, VA 22314
Email: amy.rosenthal@usda.gov
Table of Contents
Part B. Statistical Methods B-1
B.1 Respondent Universe and Sampling Methods B-1
B.2 Procedures for the Collection of Information B-3
Statistical Methodology for Stratification and Sample Selection B-4
Online Application Sub-Study B-11
Degree of Accuracy Needed for the Purpose Described in the Justification B-20
Unusual Problems Requiring Specialized Sampling Procedures B-22
Any Use of Periodic (Less Frequent Than Annual) Data Collection Cycles to Reduce Burden B-23
B.3 Methods to Maximize Response Rates and Deal with Nonresponse B-23
B.4 Test of Procedures or Methods B-27
B.5 Individuals Consulted and Individuals Collecting B-31
and Analyzing the Data
Appendices
A Applicable Statutes and Regulations
A1. Richard B. Russell National School Lunch Act of 1966
A2 Payment Integrity Information Act of 2019 (PIIA)
A3 M-15-02 – Appendix C to Circular No. A-123, Requirements for Effective Estimation and Remediation of Improper Payments
B Data Collection Instruments
B1 SFA Request for E-Records Prior School
Year
(Non-CEP Schools)
B2 SFA Reminder for E-Records Prior School
Year
(Non-CEP Schools)
Table of Contents (continued)
B3 SFA Request for E-Records Current School
Year
(Non-CEP Schools)
B4 SFA Reminder for E-Records Current School
Year
(Non-CEP Schools)
B5a Household Survey – English
B5b Household Survey-Spanish
B6a Household Survey Income Verification Worksheet – English
B6b Household Survey Income Verification Worksheet – Spanish
B7a Instructions to De-Identify and Submit Income Documentation – English
B7b Instructions to De-Identify and Submit Income Documentation – Spanish
B8 Application Data Abstraction Form
B9 Request for E-Records (CEP Schools for ISP Data Abstraction)
B10 Reminder for E-Records (CEP Schools for ISP Data Abstraction)
B11 SFA Meal Participation Data Request
B12 SFA Director Survey
B13 SFA Pre-Visit Questionnaire
B14 School Pre-Visit Questionnaire
B15 School Meal Count Verification Form
B16 SFA Meal Claim Reimbursement Verification
Form –
All Schools
B17 State Meal Claims Abstraction
B18 Meal Observation – Paper Booklet
B19 Meal Observation Pilot – Dual Camera and Paper Booklet Observations
B20 SFA Director Survey Screen Shots
C Recruitment Materials
C1 Official Study Notification from FNS Regional Liaisons to State CN Director
C2 SFA Study Notification Template
C3 SFA Study Notification and Data Request
C4 School Data Verification Reference Guide
C5 APEC IV FAQs (for States, SFAs, and Schools)
C6 SFA Follow-Up Discussion Guide (Study Notification and School Data Verification)
Table of Contents (continued)
C7 Automated Email to Confirm Receipt of School Data
C8 SFA Confirmation and Next Steps Email
C9 SFA School Sample Notification Email
C10 School Notification Email
C11 SFA Follow-Up Discussion Guide (School Sample Notification)
C12 School Study Notification Letter
C13 School Follow-Up Discussion Guide
C14 School Confirmation Email
C15 School Notification of Household Data Collection
C16a Household Survey Brochure – English
C16b Household Survey Brochure –Spanish
C17 SFA Initial Visit Contact Email
C18 SFA Data Collection Visit Confirmation Email
C19 SFA Data Collection Reminder Email
C20 School Data Collection Visit Confirmation Email
C21a School Data Collection Visit Reminder Email, Including Menu Request—1 month
C21b School Data Collection Visit Reminder Email, Including Menu Request—1 week
C22a Household Survey Recruitment Letter – English
C22b Household Survey Recruitment Letter – Spanish
C23a Household Survey Recruitment Guide – Virtual Survey – English
C23b Household Survey Recruitment Guide – Virtual Survey – Spanish
C24a Household Confirmation and Reminder of Virtual Survey-English
C24b Household Confirmation and Reminder of Virtual Survey–Spanish
C25a Household Consent Form – Virtual Survey– English
C25b Household Consent Form – Virtual Survey– Spanish
C26 Crosswalk and Summary of the Study Website
D Public Comments
D1 Public Comment 1
D2 Public Comment 2
E Response to Public Comments
E1 Response to Public Comment 1
E2 Response to Public Comment 2
Table of Contents (continued)
F National Agricultural Statistics Service (NASS) Comments and Westat Responses
G Westat Confidentiality Pledge
H Westat IRB Approval Letter
I Westat Information Technology and Systems Security Policy and Best Practices
J APEC IV Burden Table
Tables
B1-1 Respondent universe, samples, and expected response rates B-2
B2-1 Sample size for online prototype sub-study B-12
B2-2 School-level weights to be constructed B-15
B2-3 APEC III actual national estimates for certification error with confidence bounds B-22
B2-5 APEC III actual national estimates for meal claiming error with confidence bounds B-23
Figure
Exhibits
B4-1 Overview of the pilot study design B-31
B5-1 Individuals
consulted and individuals collecting and
analyzing the
data B-32
Part B. Statistical Methods
B.1 Respondent Universe and Sampling Methods
Describe (including a numerical estimate) the potential respondent universe and any sampling or other respondent selection method to be used. Data on the number of entities (e.g., establishments, State and local government units, households, or persons) in the universe covered by the collection and in the corresponding sample are to be provided in tabular form for the universe as a whole and for each of the strata in the proposed sample. Indicate expected response rates for the collection as a whole. If the collection had been conducted previously, include the actual response rate achieved during the last collection.
Respondent Universe
The respondent universe for the Fourth Access, Participation, Eligibility, and Certification Study Series (APEC IV) includes: (1) school food authorities (SFAs) and their corresponding State child nutrition (CN) agencies; (2) schools within SFAs; and (3) students and their households who applied for, or were directly certified for, meal benefits in school year (SY) 2023-2024 within the sampled schools. APEC IV includes the same respondent universe and will follow the same overall study design as APEC III, with some enhancements discussed below and in Part A.
Table B1-1 presents a summary of the universe, samples, expected response rates for each respondent type, and overall response rates. The response rate for SFAs is expected to be at least 85 percent based on the 90 percent response rate in APEC III. The response rate for schools in APEC III was 65 percent. We have raised the target response rate for schools in APEC IV to 80 percent due to enhanced recruitment strategies discussed in B3; in particular, the study website, which we expect to provide further legitimacy to the study and help with school outreach. The expected combined response rate of 75 percent for the student/household sample is based on APEC III targeted efforts to maximize response rates (described in B3 below). However, if the minimum response rate for the student/household sample is not met, we will conduct nonresponse bias analyses (described in B3). Student records (i.e., name, date of birth, identified student status, and direct certification source for identified students) from schools participating in the Community Eligibility Provision (CEP) are existing and required records; hence, the response rate will be 100 percent.
Table B1-1. Respondent universe, samples, and expected response rates
Respondent |
Universe* |
Initial |
Minimum expected response rate |
Targeted completed cases |
SFAs: |
17,540 |
336 |
85% |
286 |
Non-CEP SFAs |
12,485 |
123 |
|
105 |
CEP SFAs |
5,055 |
213 |
|
181 |
Schools: |
93,683 |
938 |
80% |
750 |
Non-CEP Schools (Non-CEP SFAs) |
51,276 |
345 |
|
276 |
Non-CEP Schools (CEP SFAs) |
11,744 |
121 |
|
97 |
CEP Schools (CEP SFAs) |
30,663 |
472 |
|
377 |
Non-CEP Students/Households: |
14,532,971 |
11,723 |
75% |
8,792 |
Non-CEP
Student Households |
10,748,048 |
8,674 |
|
6,506 |
Non-CEP Student Households (CEP SFAs) |
3,784,923 |
3,049 |
|
2,287 |
CEP School Student Records |
14,718,325 |
9,048 |
100% |
9,048 |
* Based on FY 20 FNS-742 SFA File (version dated 5-21-2021).
Sampling Overview
The overall sampling approach for APEC IV will be consistent with the previous APEC studies. The objective is to produce nationally representative estimates of error rates for NSLP and SBP that are fully compliant with the Payment Integrity Information Act of 2019 (PIIA) (P.L. 116-117) requirements. As Figure B1-1 shows, we will implement a three-tiered sampling plan in which we first select SFAs out of the 48 contiguous States and their corresponding State CN agencies, then schools within the selected SFAs, and students within the selected schools. This approach provides the estimates for the national error rates and also reduces the number of entities that are involved in the data collection and, hence, lessens the burden. Details about the sampling plan for each respondent category listed in Figure B1-1 is described in B2.
Figure B1-1. Sampling Overview |
|
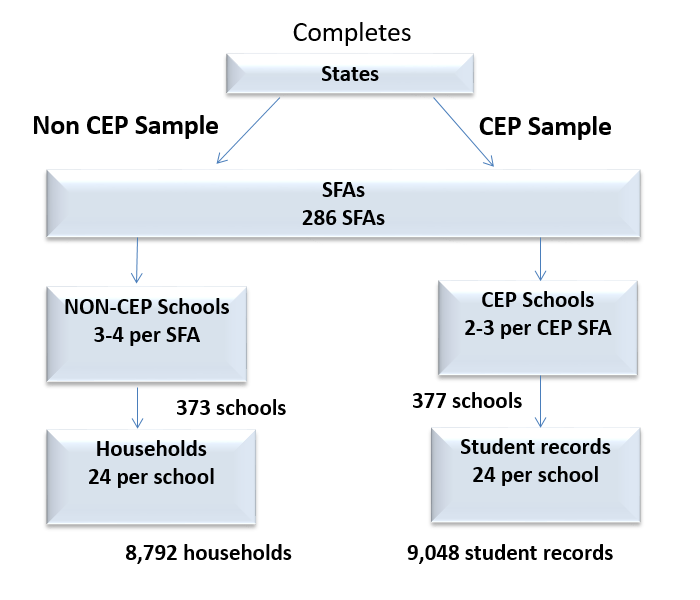
* Completes in the figure means the study participants were sampled and provided data to the study.
B.2 Procedures for the Collection of Information
Describe the procedures for the collection of information including:
Statistical methodology for stratification and sample selection;
Estimation procedure;
Degree of accuracy needed for the purpose described in the justification;
Unusual problems requiring specialized sampling procedures; and
Any use of periodic (less frequent than annual) data collection cycles to reduce burden.
APEC IV follows the same design and analysis methods as APEC III. In addition to being a replication study, APEC IV includes the following changes:
Two Rounds of Sampling for Households in Non-CEP Schools. In APEC III, it was burdensome and challenging for SFAs to provide lists of students and their eligibility status within the first few busy weeks of school. To minimize the time between certification and the household survey measuring income eligibility, data collection for measuring certification error will begin with two rounds of sampling of households for application abstraction and household surveys. The list of applicants or directly certified students from sampled schools will be requested at the end of the prior school year (SY 2022-23) and again for the current school year (after the start of SY 2023-24).
Online Application Sub-Study. This sub-study will assess whether the USDA integrity-focused online application features generate a more accurate accounting of income and household size. The household income-reporting error rate will be compared by the type of application households use to apply for free and reduced-price meals (i.e., USDA’s integrity-focused online application, online version of traditional form, or paper form).
Statistical Methodology for Stratification and Sample Selection
We will obtain two data files for sample frame construction. These include (a) the FNS-742 SFA file from a typical year of operation (potentially SY 2019-20), and (b) the Food Research and Action Center’s (FRAC) CEP Database.1 The first file contains a list of SFAs participating in the NSLP and/or SBP. This file also contains SFA-level information such as type of control (public or private), the number of schools and students participating in NSLP and SBP, the number of students certified for free and reduced-price meals, and the number of schools participating in CEP and the corresponding number of students in the CEP schools. The second data file contains information for the Local Education Agencies (LEAs) that participate in CEP, along with a list of the schools participating in CEP. Because FRAC’s CEP Database is more up to date, we will use the second file to augment the CEP-status information in the FNS-742 file.
Sampling will begin with the construction of the SFA sampling frame (i.e., universe list) that will be used to select SFAs for the study. We will first select SFAs in the 48 contiguous States and the District of Columbia to be consistent with the target population for APEC III. We will conduct various quality checks of variables reported by the SFAs in the frame. Once potential inconsistencies or possible errors are identified, we will use the National Center for Education Statistics (NCES) 2019-2020 Common Core of Data (CCD) LEA data file as the reference to determine whether there is an error in the FNS-742 frame data, and update as needed.
Next, we will extract the following data from the most recent FRAC CEP Database and attach them to the SFA records in the FNS-742 frame:
Number of schools in LEA,
Total enrollment in LEA,
Number of schools participating in CEP,
Total enrollment in CEP schools,
District-wide claiming percentages,
Number of schools participating as part of a group or district,
Number of students participating as part of a group or district,
Number of identified students (i.e., students directly certified for free meals)
Number of distinct school-level Identified Student Percentages (ISPs)2
Sampling SFAs
For sampling purposes, an SFA will be designated as “CEP” if it satisfies either of the following two conditions: (a) it is coded as having at least one CEP school in the FNS-742 frame, or (b) it appears in the FRAC CEP Database as a CEP district and has a matching SFA record in the FNS-742 frame. The latter can be considered to be new CEP SFAs because the data in the FRAC database will be more current. Finally, SFAs that consist of only Residential Child Care Institutions (RCCIs) or non-CEP SFAs that do not have any students certified for free or reduced-price meals will be dropped from the FNS frame.
Non-CEP SFAs
Certainty Non-CEP SFAs. The certainty SFAs are so large in terms of the number of students certified for free or reduced-price meals that they should be included in the sample with certainty (i.e., not subject to random sampling). Such SFAs are therefore “self-representing.” For the purpose of identifying the certainty SFAs, all non-CEP SFAs that otherwise would have a probability of selection of a certain percentage (e.g., 0.75 in APEC III) or greater under PPS (probability-proportionate-to-size) sampling will be included in the sample with certainty. We will review the FNS data to determine the threshold level PPS for certainty SFAs. Participation among all certainty SFAs (non-CEP and CEP) was very high in APEC III (only 1 of 29 declined to participate).
Noncertainty Non-CEP SFAs. To select the noncertainty SFAs, we will sort the frame of non-CEP SFAs by (a) the seven FNS Regions, (b) type of control (public/private) within region, (c) three broad enrollment size classes (<1,000, 1,000 to 9,999, and 10,000+ students) within type of control, and (d) by the sampling measure of size (MOS) (number of students certified for free or reduced-price meals), alternating from high-to-low and then low-to-high from cell to cell. Sorting the SFAs into cells based on key characteristics ensures that those selected for the sample will represent all parts of the distribution. The SFAs will be selected systematically and with probabilities proportionate to the MOS from the sorted cells. Of the noncertainty SFAs, a random systematic half sample will be designated as the “primary” sample, and the remaining half sample will be the “reserve” sample. The reserve sample will be set aside for later use if it appears that the primary sample will not yield the desired number of responding SFAs. Because they are self-representing, there will be no reserve samples for the certainty SFAs.
CEP SFAs
The approach to selecting the CEP SFAs will be generally similar to that described for the non-CEP SFAs but with the added complication that CEP SFAs can have both CEP and non-CEP schools. The first step is to construct an appropriate composite sampling measure of size for each CEP SFA in the sampling frame. This measure of size (the number of free or reduced-price certified students) is a weighted combination of two factors:
The number of students certified for free or reduced-price meals in the non-CEP schools in the SFA; and
The identified students multiplied by 1.6 (or total enrollment of the schools if that number is greater than the total enrollment in the CEP schools in the SFA).
For the CEP SFAs in the sampling frame, the composite sampling measure of size, CEPMOS, will be:
CEPMOS
=
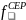 *
*
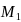 +
+
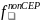 *
*
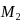
where
and
are composite weighting factors that are proportional to the
overall rates at which students in the CEP schools and non-CEP
schools, respectively, will be sampled from the CEP SFAs. Based on
the total number of students (x) we will select from the CEP schools
and total number of students (y) certified for free or reduced-price
meals from the non-CEP schools, we will use weighting factors as:
= x /
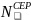 and
= y /
and
= y /
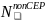 ,
where
and
are estimates of the number of students in CEP schools and
students certified for free or reduced-price meals in non-CEP
schools, respectively.
,
where
and
are estimates of the number of students in CEP schools and
students certified for free or reduced-price meals in non-CEP
schools, respectively.
Certainty CEP SFAs. For the purpose of identifying the certainty SFAs, all CEP SFAs with a probability of certain cutoff point (e.g., 75% in APEC III) under PPS sampling will be included in the sample with certainty. We will examine the size distribution and compute the cutoff point of student size to determine the certainty CEP SFAs. As noted above, the participation rate was very high among all certainty SFAs in APEC III.
Noncertainty CEP SFAs. To select the noncertainty SFAs, we will sort the frame of CEP SFAs by (a) the seven FNS Regions, (b) type of control (public/private) within region, (c) three broad enrollment size classes (<1,000, 1,000 to 9,999, and 10,000+ students) within region, and (d) by CEPMOS alternating from high-to-low and then low-to-high from cell to cell. The SFAs will be selected systematically and with probabilities proportionate to CEPMOS from the sorted file. Of the noncertainty SFAs, a random systematic half sample will be designated as the “primary” sample, and the remaining half sample will be designated as a “reserve” sample. The reserve sample will be set aside for later use if it appears that the primary sample will not yield the desired number of responding SFAs. Because they are self-representing, there will be no reserve samples for the certainty SFAs.
Sampling Schools
We will sample schools within the 286 SFAs that were sampled in the first stage. The school selection will be a function of the number of eligible schools in the SFA, the measure of size of the eligible schools in the SFA (based on the number of students with eligibility for free or reduced-price meals), and the probability of selecting the SFA in which the schools are located. Specifically, for each of the categories of schools defined by (a) SFA type (non-CEP vs. CEP) and (b) school type (non-CEP vs. CEP) within SFA, let
m = the number of sample SFAs in a given category;
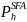 = the
probability of selecting SFA h;
= the
probability of selecting SFA h;
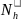 = the
total number of eligible schools reported by SFA h during
recruitment;
= the
total number of eligible schools reported by SFA h during
recruitment;
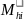 = the
MOS of school i in SFA h based on information collected
during SFA recruitment;
= the
MOS of school i in SFA h based on information collected
during SFA recruitment;
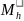 =
= 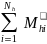 = the total MOS of all
= the total MOS of all
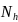 schools in SFA h;
schools in SFA h;
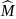 =
= 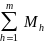 /
= the estimated total MOS based on the
/
= the estimated total MOS based on the
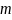 sample
SFAs; and
sample
SFAs; and
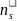 = the
number of schools of a particular type (i.e., either non-CEP school
or CEP school) to be sampled from the m sampled SFAs.
= the
number of schools of a particular type (i.e., either non-CEP school
or CEP school) to be sampled from the m sampled SFAs.
Because we want to select the schools with overall PPS, where the
size measure for school i in SFA h is defined by
,
the optimum allocation of the
schools
to SFA h is given by
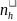 =
(
/
)
/
=
(
/
)
/ /
)
=
(
/
)
/
, (Equation
1)
/
)
=
(
/
)
/
, (Equation
1)
and the corresponding within-SFA selection probability of selecting school i in SFA h is
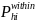 =
(
/
=
(
/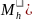 = (1/
)
(
= (1/
)
(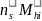 /
). (Equation 2)
/
). (Equation 2)
The within-SFA sampling rates given by equation (2) will be optimal because the resulting overall probability of selecting school i in SFA h is
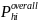 =
=
/
, (Equation
3)
=
=
/
, (Equation
3)
which is the probability of selection under a PPS sample design. The number of schools selected will vary from primary sampling unit (PSU) to PSU depending on the size.
Sampling Students
Students from Non-CEP Schools. SFAs will submit a data file of students who applied for free or reduced-price meals and students directly certified for free meals. As discussed in Part A, the list of applicants and/or directly certified students from sampled schools will be requested at the end of the prior school year (SY 2022-23) and again for the current school year (after the start of SY 2023-24). Although there will be changes in eligibility between the school years, starting with the previous year’s list will allow us to conduct the first round of sampling and recruitment earlier in the school year. This will help us to survey households within 6 weeks of their application submission, while also reducing burden on the SFAs. Using the list from the prior school year, we will sample students and ensure that the student is still eligible to participate in the study prior to conducting the household survey. For the second round (using the list from the current school year), we will replace students sampled from the first round who are no longer eligible with new eligible students. Students with no application and not directly certified (i.e., paid with no application) are not eligible for sampling because no certification error is possible for these students. The sample frame includes students in one of the following categories:
Free with application;
Free, directly certified;
Reduced-priced with application;
Reduced-price, directly certified;
Paid with application (i.e., denied); and
Paid, without application (NOT ELIGIBLE FOR SAMPLING).
Lists of study-eligible students will be created for each participating school, including a flag distinguishing between those certified for free or reduced-price meals (by application and direct certification status) and those whose application is denied. Prior to sample selection, we will sort the students by this certification status flag to ensure proportional representation of students from all eligible certification categories within schools. An equal probability sample of students will be selected from each non-CEP school at rates designed to achieve an overall self-weighting sample of students among all non-CEP schools.
Prior to sample selection, we will also sort students by family to minimize the number of students selected from any one household. However, if more than one student is sampled from a single household, both will be kept in the sample. In these cases, the student-level questions, such as participation in SBP and NSLP and perceptions of meal program quality, will be collected for each sampled student. The household-level questions, such as income, will apply to both students.
After receiving the data files, we will conduct a multi-step review, including comparison of measure of size, checking for siblings, and other general data file quality issues. In some cases, we may have to follow up with the SFAs. Next, the sampling algorithm will be applied to each school’s list.
Students from CEP Schools. In sampling student records from CEP schools, the targeted number of student records is 24 per school. We will obtain the list of students in CEP schools from the SFA (Appendix B9-B10). From the list of identified students, we will randomly select 24 students for verification.
Sampling for Online Application Sub-Study
We will conduct a sub-study to compare USDA’s online integrity-focused application features to the traditional application to determine if they generate a more complete and accurate measure of household income and family composition and, therefore, reduce certification error (see Supporting Statement Part A2). There are three forms of the application potentially available: (1) an interactive online form based on the USDA integrity-focused application prototype; (2) another online application (i.e., similar to the paper form but online); and (3) a paper application. We expect at least about 35 percent of households to complete an online application, based on APEC III findings. Further, we expect that possibly one-third of these households will have completed an online application that includes USDA integrity-focused features. Therefore, we believe that there will be enough household surveys in each of these subgroups to sustain estimates with 90 percent confidence intervals that are less than 5 percentage points (two times the national 2.5 percentage half-width upper bound). Table B2-1 presents a worst-case scenario in which we end up with only 50 SFAs that use applications with USDA integrity features. Under this scenario, the 90 percent confidence interval for the estimates for applications with integrity features is still less than 5 percentage points.
Table B2-1. Sample size for online application sub-study
Type of sampled household |
Number of SFAs |
Total
number of |
Number of households per school |
Total households |
DEFF |
Sample |
Standard error of sample |
90% Confidence Interval (CI) |
Application with USDA integrity-focused features |
50 |
114 |
4 |
456 |
1.60 |
50% |
2.97% |
±4.88% |
Other online application |
225 |
261 |
4 |
1,044 |
1.48 |
50% |
1.88% |
±3.10% |
Paper application |
275 |
374 |
7 |
2,618 |
1.59 |
50% |
1.23% |
±2.03% |
Estimation Procedures
Sample Weighting
We will create sampling weights for analysis of data obtained in APEC IV to (a) reflect the probabilities of selection at the three stages of sampling (i.e., SFAs, schools, and students/households), (b) compensate for differential rates of nonresponse at the various stages of sampling, and (c) adjust for sampling variability and potential under-coverage through post stratification (calibration). As the analyses include student, school, and SFA-level estimates, we require three sets of weights.
The construction of the required weights will be carried out sequentially starting with the SFA weights, because the weights for each subsequent stage of analysis will build on the weights computed in the previous stage. Because the weights at each level build on the previous level, we begin with a description of the methodology for constructing the SFA weights, followed by the school weights, and finally the student/household weights.
SFA Weights
An SFA-level weight is required for analysis of results from the SFA
Director Survey. The SFA weight also serves as input to creating the
school- and student-level weights discussed later. First, a base
weight,
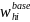 ,
equal to the reciprocal of the probability of selection under the
proposed sample design, will be assigned to each sampled SFA i in
sampling stratum h; i.e.,
,
equal to the reciprocal of the probability of selection under the
proposed sample design, will be assigned to each sampled SFA i in
sampling stratum h; i.e.,
= 1 /
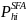 ,
(1)
,
(1)
where
=
the probability of selecting SFA i from stratum h. Note that the
sampling strata denoted by h are defined by CEP status (SFA has at
least one CEP school vs. those with no CEP schools), and
is proportional to the estimated number of students certified for
free or reduced-price lunch within the stratum. The base weights
defined above are statistically unbiased in the sense that the sum of
the base weights,
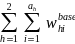 ,
summed across all of the sampled SFAs, provides an unbiased estimate
of the number of SFAs in the country.
,
summed across all of the sampled SFAs, provides an unbiased estimate
of the number of SFAs in the country.
To the extent that any of the sampled SFAs do not participate in the study for any reason, the SFA base weights will be adjusted to compensate for the loss of eligible SFAs in the sample. The adjustment will be made within weighting cells in which the predicted propensity to respond to the survey is similar. We will use Chi Square Automatic Interaction Detector (CHAID) to develop the weighting cells, using information available in the sampling frame for the sampled SFAs such as: FNS region; type of control (public/private); enrollment size class; percentage of students certified for free or reduced-price lunch; urbanicity (if available from CCD); grade span (if available); type of verification process used by the SFA to verify student eligibility; and whether the SFA has schools operating under Provision 2 or 3. The CHAID algorithm provides an effective and efficient way of identifying the significant predictors of SFA nonresponse. The primary output from the CHAID analysis will be a set of K weighting cells (defined by a subset of the predictor variables entering into the analysis) with the property that the variation in expected response propensity across the weighting cells is maximized.
Within
each of the K weighting cells determined by the CHAID analysis, an
SFA-level adjustment factor,
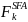 ,
will be computed as:
,
will be computed as:
=
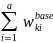 /
/
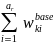 , (2)
, (2)
where the summation
in the numerator extends over all of the a sampled SFAs in weighting
cell k, whereas the summation in the denominator extends over all of
the
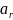 responding SFAs in the weighting cell. The final
(nonresponse-adjusted) weight,
responding SFAs in the weighting cell. The final
(nonresponse-adjusted) weight,
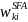 ,
for SFA i in weighting cell k to be used for analysis will then be
computed as:
,
for SFA i in weighting cell k to be used for analysis will then be
computed as:
=
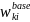 . (3)
. (3)
School Weights
We will construct eleven separate sets of school-level weights. The first set of weights (referred to as the “general” school weights) will be used to develop national estimates of school-level characteristics and will also serve as the basis for constructing the student-level weights described in the next subsection. The remaining six sets of school weights are specifically designed for analysis of aggregation error, meal claiming error, and certification error in CEP schools, and crossed by two meal types (lunch or breakfast), summarized in Table B2-3. Seven separate weights are necessary because calculating each error type requires data from different sources, and we expect the level of missing data due to nonresponse to vary for each measure. Furthermore, because the NSLP and SBP have different reimbursement amounts, weights must be budget-calibrated separately for measures of NSLP and SBP improper payments.
Table B2-2. School-level weights to be constructed
Type of error |
Meal type |
|
Lunch |
Breakfast |
|
Meal claiming error |
|
|
Aggregation error |
|
|
Certification errors in CEP schools |
|
|
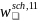
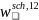
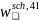
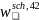
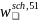
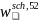
To construct the general school weights, an initial weight,
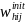 ,
representing the overall probability of selecting the school for the
sample will be computed for sampled school j in SFA i in stratum h
as:
,
representing the overall probability of selecting the school for the
sample will be computed for sampled school j in SFA i in stratum h
as:
=
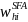 /
/
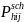 (4)
(4)
where
is the final SFA weight given by equation (3) and
is the (conditional) probability of selecting school j in SFA i in
sampling stratum h. Note that if the school is so large that it is
selected with certainty within the SFA,
=
1. Otherwise,
is proportional to the expected number of students certified for free
or reduced-price meals in the school.
To compensate for nonresponding schools, a weighting adjustment
similar to that described earlier for SFAs will be applied to the
initial school weight given by equation (4). In this case, the types
of school-level variables to be included in the CHAID analysis will
include: FNS region, CEP status of SFA, CEP status of school within
SFA, type of control, and enrollment size class of school. Based on
the CHAID analysis, a set of K weighting cells will be specified. Let
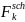 denote the nonresponse adjustment factor for the kth (k = 1, 2, ...,
K) weighting cell defined by:
denote the nonresponse adjustment factor for the kth (k = 1, 2, ...,
K) weighting cell defined by:
=
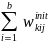 /
/
 (5)
(5)
where the summation
in the numerator extends over all of the b sampled schools in
weighting cell k, whereas the summation in the denominator extends
over all of the
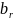 responding schools in the weighting cell. The final
(nonresponse-adjusted) school weight,
responding schools in the weighting cell. The final
(nonresponse-adjusted) school weight,
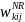 for school j in SFA i in weighting cell k will then be computed as:
for school j in SFA i in weighting cell k will then be computed as:
=
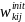 . (6)
. (6)
Note that in prior APEC studies, the nonresponse adjustment was
accomplished indirectly through post stratification to “best
estimates” of the numbers of study-eligible schools in SFAs. To
implement such an adjustment, reliable independent estimates of the
numbers of study-eligible schools are required to serve as
control totals in post stratification. Assuming that such control
totals are available from FNS administrative files (or can be
estimated with high precision), let
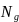 =
the “known” number of study-eligible schools in the
population for poststratum g, where the poststrata are the four
subgroups of schools defined by (1) private schools, (2) public
schools with enrollment under 500, (3) public schools with enrollment
between 500 and 999, and (4) public schools with enrollment of 1,000
or greater. Within poststratum g (g = 1, 2, ..., 4), a post
stratification adjustment factor,
=
the “known” number of study-eligible schools in the
population for poststratum g, where the poststrata are the four
subgroups of schools defined by (1) private schools, (2) public
schools with enrollment under 500, (3) public schools with enrollment
between 500 and 999, and (4) public schools with enrollment of 1,000
or greater. Within poststratum g (g = 1, 2, ..., 4), a post
stratification adjustment factor,
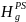 ,
will be computed as:
,
will be computed as:
=
/
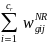 , (7)
, (7)
where the summation
in the denominator extends over all of the
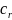 responding schools in poststratum g. The final (poststratified)
general school weight,
responding schools in poststratum g. The final (poststratified)
general school weight,
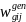 ,
for school j in SFA i in poststratum g, will then be computed as:
,
for school j in SFA i in poststratum g, will then be computed as:
=
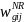 . (8)
. (8)
In
addition to the general school weights, we will construct six sets of
special school weights, as indicated in Table B2-3.. The basic steps
for constructing a particular set of special school weights
corresponding to type of error (e) and meal type (m), say
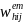 ,
are as follows. The starting point is the set of general weights
given by equation (8). Thus, each responding school j in SFA i in
stratum h in the sample is first assigned a preliminary weight,
,
are as follows. The starting point is the set of general weights
given by equation (8). Thus, each responding school j in SFA i in
stratum h in the sample is first assigned a preliminary weight,
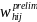 =
=
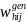 .
(9)
.
(9)
For analyses of school characteristics that are unrelated to student meal program participation, a school-level nonresponse adjustment factor will be computed to account for responding schools that did not provide the data necessary to calculate the required error rate. That is, within the following nine cells defined by FNS region and CEP status: (a) seven cells consisting of non-CEP schools in non-CEP SFAs in each of the seven FNS regions; (b) one cell defined by non-CEP schools in CEP SFAs; and (c) one cell defined by CEP schools in CEP SFAs, a nonresponse adjustment factor will be computed as:
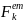 =
=
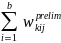 /
/
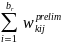 , (10)
, (10)
where the summation
in the numerator extends over all of the b sampled schools in
weighting cell k, whereas the summation in the denominator extends
over all of the
schools in the weighting cell with complete data required to
calculate error type e for meal type m. The
nonresponse-adjusted school weight,
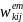 ,
for school j in SFA i in weighting cell k will then be computed as:
,
for school j in SFA i in weighting cell k will then be computed as:
=
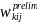 . (11)
. (11)
For analyses of school characteristics that are related to student
meal program participation (e.g., reimbursements and improper
payments), an additional post stratification adjustment will be
implemented to align the weighted counts of students in the sampled
schools to the corresponding national student counts within twelve
categories of schools defined by cross-classifying three enrollment
size classes (under 500, 500 to 999, and over 1,000 students) and
four levels of the percentage of students certified for free or
reduced price meals (less than 25%, 26-50%, 51-75%, and over 75%).
The control totals required for post stratification will be derived
from NCES data sources (e.g., the CCD for public schools and Private
School Survey).3,4
Let
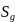 denote the national count of students in poststratum g. The
poststratification adjustment factor for poststratum g will be
computed as:
denote the national count of students in poststratum g. The
poststratification adjustment factor for poststratum g will be
computed as:
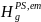 =
/
=
/
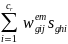 (12)
(12)
where
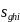 =
the number of students reported in the survey by school j in SFA i in
sampling stratum h, and where the summation in the denominator
extends over all of the
responding schools corresponding to error type e and meal type m in
poststratum g. The poststratified school weight,
=
the number of students reported in the survey by school j in SFA i in
sampling stratum h, and where the summation in the denominator
extends over all of the
responding schools corresponding to error type e and meal type m in
poststratum g. The poststratified school weight,
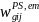 ,
for school j in SFA i in poststratum g will then be computed as:
,
for school j in SFA i in poststratum g will then be computed as:
=
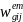 . (13)
. (13)
The final step will be to “calibrate” the school weights
given by (13) so that sample-based weighted estimates of
reimbursements equals known reimbursement totals from FNS
administrative files. This adjustment will be applied to each of the
eight sets of school weights,
.
Let
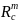 =
the total annual reimbursement amount derived from FNS administrative
files for meal type m (breakfast or lunch) and school type c (CEP vs.
non-CEP). The final calibrated weight to be used for analysis of
payment errors for school j in school-type c and meal type m will be
computed as:
=
the total annual reimbursement amount derived from FNS administrative
files for meal type m (breakfast or lunch) and school type c (CEP vs.
non-CEP). The final calibrated weight to be used for analysis of
payment errors for school j in school-type c and meal type m will be
computed as:
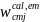 =
=
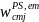 {
/
{
/
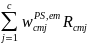 } (13a)
} (13a)
where
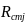 =
the total annual reimbursement reported by responding school j in
school-type c for meal type m.
=
the total annual reimbursement reported by responding school j in
school-type c for meal type m.
Student (Household) Weights
Estimates of certification errors in non-CEP schools will be based on responses to the Household Survey. The final student weights will include an adjustment for nonresponse and a post stratification adjustment to align the sample-based weighted estimates of dollar reimbursement amounts to the corresponding known population amounts available from FNS administrative files.
The starting point for constructing the required student weights is
the assignment of an initial student weight to the responding
students in the sample. For students selected from the non-CEP
schools, the term “responding student” refers to the
response status of the household in which the student resides, as it
is information from the household survey that will be used to
determine improper payments. The initial student weight,
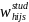 ,
for student s in school j of SFA i in sampling stratum h will be
computed as:
,
for student s in school j of SFA i in sampling stratum h will be
computed as:
=
/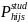 (14)
(14)
where
=
the general school weight defined by equation (8) and
is the (conditional) probability of selecting student s from school j
in SFA i in sampling stratum h. The (within-school) probability of
selecting a student for the sample will depend on whether the sampled
school is a CEP or non-CEP school, and within the CEP schools, will
also depend on the certification status of the student. The values of
will be known at the time of sampling.
Next, a nonresponse adjustment will be applied to the initial weights (equation 14) to compensate for sample losses due to incomplete student-level data. Weighting cells will be defined by type of control, CEP status of SFA in which school is located, and certification status of student (i.e., certified for free/reduced-price lunch vs. denied). These are broadly consistent with the variables used in APEC III to form nonresponse weighting cells; however, we will also consider other variables (e.g., derived from the household survey as appropriate). Within final weighting cell k, a nonresponse adjustment factor will be computed as:
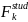 =
=
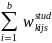 /
/
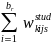 , (15)
, (15)
where the summation
in the numerator extends over all of the b sampled students in
weighting cell k, whereas the summation in the denominator extends
over all of the
“responding students” in the weighting cell (i.e., those
for which the household provides sufficiently complete data for
calculation of improper payments for the sampled student). The
nonresponse-adjusted student weight,
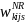 ,
for student s in (non-CEP) school j in SFA i in weighting cell k will
then be computed as:
,
for student s in (non-CEP) school j in SFA i in weighting cell k will
then be computed as:
=
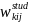 . (16)
. (16)
The final step in student weighting will be to calibrate the
nonresponse-adjusted weights given by (16) so that sample-based
weighted estimates of total (annual) reimbursements equals the
corresponding “known” amounts recorded in FNS data files.
This adjustment will be made separately for NSLP and SBP. Let
=
the total annual reimbursement amount derived from FNS administrative
files for meal type m (breakfast or lunch) and school type c
(non-CEP). The final calibrated weight for student s in school j in
school type c and meal type m will be computed as:
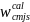 =
=
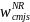 {
/
{
/
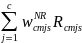 } (16a)
} (16a)
where
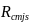 =
the total annual reimbursement reported by responding student s in
school j in school-type c for meal type m.
=
the total annual reimbursement reported by responding student s in
school j in school-type c for meal type m.
We will calculate the sample variances of the estimates using replicate weights and the jackknife repeated replication method. Using replication and replicate weights is a computationally efficient method for calculating sampling variance.5 Conceptually, the method emulates the variation that would occur if one sampled and collected the data repeated times. When the jackknife variance estimation procedure is implemented, we obtain approximately unbiased estimates of sampling variance.
Degree of Accuracy Needed for the Purpose Described in the Justification
In PIIA reporting, the government requires a sampling design based on 90 percent confidence intervals of plus or minus 2.5 percentage points around the national estimates of error rates. The statistical goal is to provide precise estimates of error rates and sources for the program.
Tables
B2-4, B2-5, and B2-6 present the realized standard errors and 90
percent confidence bounds from APEC III for overall certification
type improper payment rates, overall aggregation type improper
payment rates, and overall meal claiming type error rates. As we
assumed for APEC III, the sampling precision of estimates of improper
payment rates derived from the household survey and student
application records will depend on the underlying standard deviation
of the error rates () among
all applications in the population, as well as the design effects due
to clustering (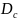 )
and unequal weighting (
)
and unequal weighting (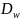 ).
Based on estimates of standard errors reported in the APEC III final
report, we have assumed that the values of
will range from 0.30 to 0.56 for NSLP and from 0.28 to 0.63 for SBP,
depending on whether the error rate being computed is an overpayment,
underpayment, net error rate, or gross error rate. The design effect
due to clustering is given approximately by the formula (e.g., see
equation 2.23 of Skinner, Holt, and Smith, 19896):
).
Based on estimates of standard errors reported in the APEC III final
report, we have assumed that the values of
will range from 0.30 to 0.56 for NSLP and from 0.28 to 0.63 for SBP,
depending on whether the error rate being computed is an overpayment,
underpayment, net error rate, or gross error rate. The design effect
due to clustering is given approximately by the formula (e.g., see
equation 2.23 of Skinner, Holt, and Smith, 19896):
= 1 + (m-1)n1
+ (n-1)2,
where m = the average number of sample schools per SFA, n
= the average number of sample students (i.e., either households or
student-records) per school, 1
= the intraclass correlation within PSUs, and 2
= the intraclass correlation within schools. For sample planning
purposes, we have assumed that both 1
and 2
are both of the order of 0.02, which we believe are likely to be
conservative assumptions. Finally, we assume an unequal weighting
effect of
=
1.40 for both NSLP and SBP, which is also a conservative estimate.
The sample sizes used in APEC III are sufficient to meet PIIA requirements and will remain the same for APEC IV.
Table B2-3. APEC III actual national estimates for improper payments due to certification error with confidence bounds
Program |
Type
of improper |
Estimated percentage |
APEC III standard error |
90% Confidence bounds |
NSLP |
Gross improper payment |
6.52% |
0.56% |
±0.92% |
Overpayment |
5.33% |
0.49% |
±0.81% |
|
Underpayment |
1.19% |
0.30% |
±0.49% |
|
Net improper payment |
4.15% |
0.51% |
±0.84% |
|
SBP |
Gross improper payment |
6.29% |
0.63% |
±1.04% |
Overpayment |
5.15% |
0.56% |
±0.92% |
|
Underpayment |
1.14% |
0.28% |
±0.46% |
|
Net improper payment |
4.01% |
0.57% |
±0.94% |
Table B2-4. APEC III actual national estimates for improper payments due to aggregation error with confidence bounds
Program |
Type
of improper |
Estimated percentage |
APEC III standard error |
90% Confidence bounds |
NSLP |
Gross improper payment |
1.50% |
0.29% |
±0.48% |
Overpayment |
0.72% |
0.22% |
±0.36% |
|
Underpayment |
0.78% |
0.20% |
±0.33% |
|
Net improper payment |
-0.06% |
0.30% |
±0.49% |
|
SBP |
Gross improper payment |
2.11% |
0.50% |
±0.82% |
Overpayment |
1.29% |
0.45% |
±0.74% |
|
Underpayment |
0.82% |
0.23% |
±0.38% |
|
Net improper payment |
0.46% |
0.50% |
±0.82% |
Table B2-5. APEC III actual national estimates for meal claiming error with confidence bounds
Program |
Type of error rate |
Estimated percentage |
APEC III standard error |
90% confidence bounds |
NSLP |
Gross error rate |
7.62% |
0.70% |
±1.15% |
Overclaiming rate |
5.04% |
0.53% |
±0.87% |
|
Underclaiming rate |
2.57% |
0.49% |
±0.81% |
|
Net error rate |
2.47% |
0.74% |
±1.22% |
|
SBP |
Gross error rate |
12.36% |
0.96% |
±1.58% |
Overclaiming rate |
11.17% |
0.88% |
±1.45% |
|
Underclaiming rate |
1.19% |
0.43% |
±0.71% |
|
Net error rate |
9.98% |
1.00% |
±1.64% |
Unusual Problems Requiring Specialized Sampling Procedures
There are no unusual problems that require specialized sampling procedures for the sampling of SFAs, schools, or students/households. However, it is important to note that in APEC III, we found that it was burdensome and challenging for SFAs to provide the data file with student eligibility information within the first few busy weeks of school. In many cases, we received the data files many months after the start of school. For APEC IV, we will request the student list from SFAs prior to the start of SY 2023-24, in April 2023, and then a second time after October 1 of SY 2023-24. Thus, the sampling at the student level for the household survey and application abstraction will be conducted in two rounds.
Any Use of Periodic (Less Frequent Than Annual) Data Collection Cycles to Reduce Burden
The data collection effort, with multiple visits to SFAs and schools, is planned to be done one time only during the 2023-24 school year. The data collection cycle comprises recruitment and data collection activities. Supporting Statement A provides a summary of data collection procedures.
B.3 Methods to Maximize Response Rates and Deal with Nonresponse
Describe methods to maximize response rates and deal with issues of non-response. The accuracy and reliability of information collected must be shown to be adequate for intended uses. For collections based on sampling, a special justification must be provided for any collection that will not yield “reliable” data that can be generalized to the universe studied.
As reported in Table B1-1, a 90 percent response rate is expected for SFAs, between a 65 and 100 percent response rate is expected for schools, and a 75 percent response rate is expected for students/households. Based on experience with APEC III, we anticipate response rates to be higher among SFAs and schools than households.
Similar to APEC III household recruitment, Westat will work with SFA directors and school principals to ensure that school staff confirm the legitimacy of the study if households contact the school for verification. As discussed in Part A, we will provide the household survey brochure to schools so that it can be shared with school staff and parents to inform them about the study and direct interested individuals to the study website. We will also encourage school principals to notify school administrative staff so that they can confirm the legitimacy of the study with parents who may contact the school with questions.
While APEC IV recruitment will be similar to APEC III, there will be three enhancements to help increase response rates among households. First, Westat will create a study website to serve as a central location of information for all study participants. This website will serve to increase the legitimacy of the study and increase potential participants’ comprehension of the study. Second, recruitment of households in non-CEP schools will begin earlier in the school year compared to APEC III. Third, the household survey will be conducted virtually, rather than in person as in APEC III.
In addition, to enhance SFA and school recruitment and participation, APEC IV will provide SFAs with access to a dashboard on the study website to track and monitor their completion of data collection activities, both at the SFA and school level.
Although we will make efforts to achieve as high a response rate as practicable with the available resources, nontrivial nonresponse losses can occur. As specified in the Standards and Guidelines for Statistical Surveys published by the Office of Management and Budget, a nonresponse bias analysis (NRBA) is required if the overall unit response rate for a survey is less than 80 percent (Guideline 3.2.9). Based on the experiences of previous APEC studies, this is unlikely to be an issue for the data collection from SFAs or schools, but may be for the household survey with parents/guardians. In APEC III, the NRBA identified no systematic nonresponse bias.
For APEC IV, the overall household survey response rate is the product of the response rates at each of the following three stages of sampling: SFAs, schools, and households. In general, compensation for nonresponse in sample surveys will be handled by weight adjustments at each stage of selection. The purpose of the NRBA is to assess the impact of nonresponse on the survey estimates and the effectiveness of the weight adjustments to lessen potential nonresponse biases.
The types of analyses to be conducted to evaluate possible nonresponse biases will include:
Comparing characteristics of non-respondents (or the total sample) to those of respondents using information available for both non-respondents and respondents. As required, this analysis will be conducted in stages for each of the three relevant sampling units: SFAs, schools, and households. For example, to assess the impact of nonresponse at the SFA level, we will obtain data from the FNS-742 SFA frame along with information from the NCES CCD district universe files (e.g., type and size of SFA, number of schools eligible for NSLP and SBP, region, urbanicity, racial/ethnic composition of school district, poverty status, percentage of students certified for free or reduced meals, etc.). We will use these data to examine differences in characteristics between the responding and nonresponding SFAs. Within the responding SFAs, similar comparisons between the responding and nonresponding schools will be made using data available in the school frames such as size and grade level of school, minority composition, percentage of students certified for free or reduced-price meals, plus selected district-level characteristics. Finally, within the participating schools, we will assess differences between the responding and nonresponding households using data available from applications such as size of household, race/ethnicity, number of children attending school, and income.
Modeling response propensity using multivariate analyses. For each of the three types of sampling units, we will apply logistic regression models and CHAID analysis to identify the significant predictors of nonresponse, using variables available from the respective sample frame as independent variables in the models. This analysis will inform the specification of nonresponse weighting classes that will be used to adjust the sampling weights. We will use CHAID to develop the weighting cells, using information available in the sampling frame for the sampled SFAs such as: FNS region, type of control (public/private), enrollment size class, percentage of students certified for free or reduced-price meals (in categories), urbanicity (if available from CCD), grade span (if available), and possibly others. The CHAID algorithm provides an effective and efficient way of identifying the significant predictors of SFA nonresponse.
Evaluating differences found in comparisons between unadjusted (i.e., base-) weighted estimates of selected sampling frame characteristics based on the survey respondents and the corresponding population (frame) parameter. In the absence of nonresponse, the unadjusted weighted estimates are unbiased estimates of the corresponding population parameters. This analysis provides an alternative way of assessing how nonresponse may have impacted the distribution of the respondent sample and thus potentially affects the sample-based estimates.
Comparing weighted survey estimates (e.g., selected error rates by type) using unadjusted (base) weights versus nonresponse-adjusted weights. This analysis will be conducted after the final nonresponse-adjusted weights are developed and will provide a measure of how well the weight adjustments have compensated for differential nonresponse.
If the sample members differ in characteristics from the population, we account for this in developing the survey weights. (See B2 for more complete discussion of sample weight development.)
B.4 Test of Procedures or Methods
Describe any tests of procedures or methods to be undertaken. Testing is encouraged as an effective means of refining collections of information to minimize burden and improve utility. Tests must be approved if they call for answers to identical questions from 10 or more respondents. A proposed test or set of tests may be submitted for approval separately or in combination with the main collection of information.
The APEC IV instruments are based on those used in APEC III. Therefore, there was no need to conduct comprehensive cognitive testing on all instruments. Instead, pretesting focused on 1) evaluating new protocols for household survey income verification and requests to SFAs for student lists for household sampling and 2) streamlining and clarifying the SFA Director Survey and Household Survey. In addition, a new method of meal observation will be pretested once school meal procedures return to pre-COVID operations.
Household Survey Income Verification. The household survey asks questions about respondents’ benefits and/or income and requests that they present documentation to verify their income. In previous APEC studies, the data were collected in person. In APEC IV, however, the household surveys will be conducted via secure video call, either the video call option or the dial-in number option. For submitting income documentation for verification, we will offer respondents two options:
Option 1. Use the video option to show the interviewer the documentation.
Option 2. Submit the documentation via email message or text message. We will provide the respondent with a unique ID to submit their de-identified income documentation to the study, with the following guidelines:
Redact their personally identifiable information (e.g., name, address, social security number) from the income documentation.
Take a picture or scan the redacted income documentation and send it to the study’s email or text, along with their unique ID.
Westat recruited nine respondents to pretest the procedures for providing mock income documentation virtually, either by holding up the mock income documentation during a video call or by redacting the mock income documentation and sending an image of it via text message or email. The goals of this pretest were two-fold: (1) to determine whether the survey administrator can clearly see the necessary information via video, and (2) to assess whether participants understand the instructions provided to redact and submit the income documentation via text message or email.
Overall, most of the pretest respondents had no issues with understanding and following the detailed instructions they received for redacting and sending the mock income documentation via text message or email. In addition, the survey administrator had no issues with viewing the mock income documentation via video call. Based on the respondent feedback from the pretest, Westat updated the instructions for submitting income documentation to be more streamlined and clear.
SFA Data Request. In APEC III, we found that it was burdensome and challenging for SFA directors to provide the student roster files with student eligibility for free and reduced-price meals within the busy first few weeks of school. For APEC IV, we planned to initially request a student roster list from the SFA directors before the end of SY 2022-23, around May 2023, and then a second time in the new school year, after October 1, 2023, of SY 2023-24. Westat pretested the feasibility of this data collection strategy by asking six SFAs to provide feedback on submitting student rosters twice, once in May and once in October. Based on the results of the pretest, Westat has updated the first data request to occur in April instead of May, and we will provide 3-4 weeks for SFAs to prepare and submit the student lists. In addition, Westat made edits to the instructions to provide more clarity on the data elements that are required versus those that are optional. Further, for any district that struggles to complete their files by the given deadline, we will allow SFAs the opportunity to determine the timing in which to submit the student list based on when it is at least 80 percent complete.
SFA Director Survey and the Household Survey. Two experienced survey methodologists reviewed the SFA Director Survey and Household Survey to evaluate wording choices, the breadth of response options, and the flow and formatting of questions. Based on their feedback, the order of the questions in the SFA Director Survey was revised, and double-barreled questions were split into multiple questions. In addition, key definitions included in the survey were edited for clarity. Questions on the Household Survey were reworded to be clearer and to reduce the cognitive burden on the respondents.
Meal Observations. A new method of meal observations will be pilot tested in 9 or fewer schools. The pilot study will assess the feasibility of using cameras to record student trays rather than using in-person tray observations with paper booklets. Data collectors will be trained to collect meal observation data with the paper booklets used in prior APEC studies as well as with cameras. In seven of the nine schools, we will conduct dual-method observations of approximately 1,400 meal trays (the same trays will be captured by both methods) to facilitate a comparison of the data (see Exhibit B4-1). In two of the nine schools, we will use only a camera to capture meal tray components. (See Appendix B19 for more detail around the data collection methods for the pilot study.) The pilot study will answer three questions:
How do the two methods compare with regard to the accuracy of the data collected?
How do the two methods compare with regard to cost?
What are the possibilities for scaling up the new method of data collection?
Exhibit B4-1. Overview of the pilot study design
Pilot study component |
Dual-method observations |
Camera-only observations |
Primary goal |
|
|
Data collection |
|
|
Analyses |
|
|
The camera pilot test will be included as part of the main data collection during SY 2023-24. Results will be used to inform the use of the camera method in future FNS studies.
B.5 Individuals Consulted and Individuals Collecting and Analyzing the Data
Provide the name and telephone number of individuals consulted on statistical aspects of the design and the name of the agency unit, contractor(s), grantee(s), or other person(s) who will actually collect and/or analyze the information for the agency.
The information will be collected and analyzed by Westat (see Exhibit B5-1). The statistical procedures have been reviewed by Jeffrey Hunt with USDA’s National Agricultural Service (NASS). Comments from NASS are included in Appendix F and responses are incorporated into the supporting statement.
Exhibit B5-1. Individuals consulted and individuals collecting and analyzing the data
Westat staff (contractor) |
Title |
Phone number |
Roline Milfort, Ph.D., PMP |
Senior Study Director |
301-251-8229 |
Laurie May, Ph.D. |
Vice President, Associate Director |
301-517-4076 |
Mustafa Karakus, Ph.D. |
Senior Economist |
301-294-2874 |
Roger Tourangeau, Ph.D. |
Senior Statistician |
301-294-2828 |
Lindsay Giesen, M.P.H. |
Senior Study Director |
240-453-5693 |
Jeffrey Taylor, Ph.D. |
Senior Study Director |
301-212-2174 |
Alice Ann Gola, Ph.D. |
Senior Study Director |
703-517-3306 |
FNS Staff |
||
Amy Rosenthal, Ph.D. |
Social Science Research Analyst |
703-305-2245 |
Conor McGovern |
Chief, Special Nutrition Evaluation Branch |
703-457-7740 |
NASS Staff |
||
Jeffrey Hunt |
Mathematical Statistician |
202-720-5359 |
2 Each distinct ISP represents a school or group of schools operating CEP. To operate CEP, a school or group of schools must have an ISP of at least 40%.
3 Common Core of Data (CCD). America’s Public Schools. https://nces.ed.gov/ccd/pubschuniv.asp
4 Private School Universe Survey (PSS). National Center for Education Statistics. https://nces.ed.gov/surveys/pss/pssdata.asp
5Rust, K. F., and Rao, J. (1996). Variance estimation for complex surveys using replication techniques. Statistical Methods in Medical Research, 5:283-310.
6 Skinner, C. J., Holt, D., and Smith, T. M. F. (Eds.). (1989). Analysis of Complex Surveys. New York: John Wiley and Sons.
| File Type | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
| File Title | 2020-000: |
| Author | Chantell Atere |
| File Modified | 0000-00-00 |
| File Created | 2022-08-24 |
© 2026 OMB.report | Privacy Policy