Attachment E - Voting and Registration Source and Accuracy Statement
Attach E - Voting and Registration_S&A.docx
Current Population Survey, Voting and Registration Supplement
Attachment E - Voting and Registration Source and Accuracy Statement
OMB: 0607-0466
MEMORANDUM FOR: Lisa Clement
Survey Director for CPS & Time Use
Associate Directorate for Demographic Programs
From: James B. Treat
Chief, Demographic Statistical Methods Division
Subject: Source and Accuracy Statement for the November 2014 CPS Microdata File on Voting and Registration - Revision
Attached is the revised statement on the source of the data and accuracy of the estimates for the November 2014 CPS Microdata File on Voting and Registration. This revision corrects the parameters in Tables 4, 5, 6, and 7.
If you have any questions or need additional information, please contact Rebecca Hoop of the Demographic Statistical Methods Division via email at dsmd.source.and.accuracy@census.gov.
Attachment
cc:
G. Weyland (DSD)
J. Back
K. Linse
J. Ortman (SEHSD)
K. Bauman
T. File
W. Savino (ACSD)
D. Smallwood
J. Farber (DSMD)
T. Kennel
Y. Cheng
J. Scott
D. Hornick
R. Hoop
S. Clark
1Source of the Data and Accuracy of the Estimates for the
November 2014 CPS Microdata File on Voting and Registration
Table of Contents
SOURCE OF THE DATA 1
Basic CPS 1
November 2014 Supplement 2
Estimation Procedure 2
ACCURACY OF THE ESTIMATES 3
Sampling Error 3
Nonsampling Error 3
Nonresponse 3
Sufficient Partial Interview 4
Coverage 4
Comparability of Data 5
A Nonsampling Error Warning 6
Standard Errors and Their Use 6
Estimating Standard Errors 7
Generalized Variance Parameters 7
Standard Errors of Estimated Numbers 9
Standard Errors of Estimated Percentages 9
Standard Errors of Estimated Differences 10
Standard Errors for State, Division, and Region Estimates 11
Technical Assistance 12
REFERENCES 20
Tables
Table 1. CPS Coverage Ratios: November 2014 5
Table 2. Estimation Groups of Interest and Generalized Variance Parameters 8
Table 3. Parameters for Computation of Standard Errors for Labor Force Characteristics:
November 2014 13
Table 4. Parameters for Computation of Standard Errors for Voting and Registration
Characteristics: November 2014 14
Table 5. Parameters for Computation of State Standard Errors: November 2014 15-16
Table 6. Parameters for Computation of Division Standard Errors: November 2014 17
Table 7. Parameters for Computation of Region Standard Errors: November 2014 17
Table 8. Factors and Populations for State Parameters: November 2014 18
Table 9. Factors and Populations for Division Parameters: November 2014 19
Table 10. Factors and Populations for Region Parameters: November 2014 19
1Source of the Data and Accuracy of the Estimates for the
November 2014 CPS Microdata File on Voting and Registration
SOURCE OF THE DATA
The data in this microdata file are from the November 2014 Current Population Survey (CPS). The U.S. Census Bureau conducts the CPS every month, although this file has only November data. The November survey uses two sets of questions, the basic CPS and a set of supplemental questions. The CPS, sponsored jointly by the Census Bureau and the U.S. Bureau of Labor Statistics, is the country’s primary source of labor force statistics for the entire population. The Social, Economic, and Housing Statistics Division of the Census Bureau sponsors the supplemental questions for November.
1Basic CPS. The monthly CPS collects primarily labor force data about the civilian noninstitutionalized population living in the United States. The institutionalized population, which is excluded from the population universe, is composed primarily of the population in correctional institutions and nursing homes (98 percent of the 4.0 million institutionalized people in Census 2010). Interviewers ask questions concerning labor force participation about each member 15 years old and over in sample households. Typically, the week containing the nineteenth of the month is the interview week. The week containing the twelfth is the reference week (i.e., the week about which the labor force questions are asked).
The CPS uses a multistage probability sample based on the results of the decennial census, with coverage in all 50 states and the District of Columbia. The sample is continually updated to account for new residential construction. When files from the most recent decennial census become available, the Census Bureau gradually introduces a new sample design for the CPS.
Every ten years the CPS first stage sample is redesigned 1 reflecting changes based on the most recent decennial census. In the first stage of the sampling process, primary sampling units (PSUs)2 were selected for sample. In the 2000 design, the United States was divided into 2,025 PSUs. These were then grouped into 824 strata and one PSU was selected for sample from each stratum. In the 2010 sample design, the United States was divided into 1,987 PSUs. These PSUs were then grouped into 852 strata. Within each stratum, a single PSU was chosen for the sample, with its probability of selection proportional to its population as of the most recent decennial census. In the case of strata consisting of only one PSU, the PSU was chosen with certainty.
In April 2014, the Census Bureau began phasing out the 2000 sample and replacing it with the 2010 sample, creating a mixed sampling frame. Two simultaneous changes occur during this phase-in period. First, within the PSUs selected for both the 2000 and 2010 designs, sample households from the 2010 design gradually replace sample households from the 2000 design. Second, new PSUs selected for only the 2010 design gradually replace outgoing PSUs selected for only the 2000 design. By July 2015, the new 2010 sample design will be completely implemented and the sample will come entirely from the 2010 redesigned sample.
Approximately 74,000 housing units were selected for sample from the sampling frame in November. Based on eligibility criteria, 11 percent of these housing units were sent directly to computer-assisted telephone interviewing (CATI). The remaining units were assigned to interviewers for computer-assisted personal interviewing (CAPI).3 Of all housing units in sample, about 62,000 were determined to be eligible for interview. Interviewers obtained interviews at about 55,000 of these units. Noninterviews occur when the occupants are not found at home after repeated calls or are unavailable for some other reason.
1November 2014 Supplement. In November 2014, in addition to the basic CPS questions, interviewers asked supplementary questions of all persons 18 years of age and older on voting and registration.
1Estimation
Procedure. This survey’s estimation procedure adjusts
weighted sample results to agree with independently derived
population estimates of the civilian noninstitutionalized population
of the United States and each state (including the District of
Columbia). These population estimates, used as controls for the CPS,
are prepared monthly to agree with the most current set of population
estimates that are released as part of the Census Bureau’s
population estimates and projections program.
The population controls for the nation are distributed by demographic characteristics in two ways:
Age, sex, and race (White alone, Black alone, and all other groups combined).
Age, sex, and Hispanic origin.
The population controls for the states are distributed by race (Black alone and all other race groups combined), age (0-15, 16-44, and 45 and over), and sex.
The independent estimates by age, sex, race, and Hispanic origin, and for states by selected age groups and broad race categories, are developed using the basic demographic accounting formula whereby the population from the 2010 Census data is updated using data on the components of population change (births, deaths, and net international migration) with net internal migration as an additional component in the state population estimates.
The net international migration component of the population estimates includes:
Net international migration of the foreign born;
Net migration between the United States and Puerto Rico;
Net migration of natives to and from the United States; and
Net movement of the Armed Forces population to and from the United States.
Because the latest available information on these components lags the survey date, it is necessary to make short-term projections of these components to develop the estimate for the survey date.
1ACCURACY OF THE ESTIMATES
A sample survey estimate has two types of error: sampling and nonsampling. The accuracy of an estimate depends on both types of error. The nature of the sampling error is known given the survey design; the full extent of the nonsampling error is unknown.
Sampling Error. Since the CPS estimates come from a sample, they may differ from figures from an enumeration of the entire population using the same questionnaires, instructions, and enumerators. For a given estimator, the difference between an estimate based on a sample and the estimate that would result if the sample were to include the entire population is known as sampling error. Standard errors, as calculated by methods described in “Standard Errors and Their Use,” are primarily measures of the magnitude of sampling error. However, they may include some nonsampling error.
Nonsampling Error. For a given estimator, the difference between the estimate that would result if the sample were to include the entire population and the true population value being estimated is known as nonsampling error. There are several sources of nonsampling error that may occur during the development or execution of the survey. It can occur because of circumstances created by the interviewer, the respondent, the survey instrument, or the way the data are collected and processed. For example, errors could occur because:
• The interviewer records the wrong answer, the respondent provides incorrect information, the respondent estimates the requested information, or an unclear survey question is misunderstood by the respondent (measurement error).
• Some individuals who should have been included in the survey frame were missed (coverage error).
• Responses are not collected from all those in the sample or the respondent is unwilling to provide information (nonresponse error).
• Values are estimated imprecisely for missing data (imputation error).
• Forms may be lost, data may be incorrectly keyed, coded, or recoded, etc. (processing error).
To minimize these errors, the Census Bureau applies quality control procedures during all stages of the production process including the design of the survey, the wording of questions, the review of the work of interviewers and coders, and the statistical review of reports.
Two types of nonsampling error that can be examined to a limited extent are nonresponse and undercoverage.
Nonresponse. The effect of nonresponse cannot be measured directly, but one indication of its potential effect is the nonresponse rate. For the November 2014 basic CPS, the household-level nonresponse rate was 11.0 percent. The person-level nonresponse rate for the Voting and Registration supplement was an additional 6.3 percent. Since the basic CPS nonresponse rate is a household-level rate and the Voting and Registration supplement nonresponse rate is a person-level rate, we cannot combine these rates to derive an overall nonresponse rate. Nonresponding households may have fewer persons than interviewed ones, so combining these rates may lead to an overestimate of the true overall nonresponse rate for persons for the Voting and Registration supplement.
Sufficient Partial Interview. A sufficient partial interview is an incomplete interview in which the household or person answered enough of the questionnaire for the supplement sponsor to consider the interview complete. The remaining supplement questions may have been edited or imputed to fill in missing values. Insufficient partial interviews are considered to be nonrespondents. Refer to the supplement overview attachment in the technical documentation for the specific questions deemed critical by the sponsor as necessary to be answered in order to be considered a sufficient partial interview.
1Coverage. The concept of coverage in the survey sampling process is the extent to which the total population that could be selected for sample “covers” the survey’s target population. Missed housing units and missed people within sample households create undercoverage in the CPS. Overall CPS undercoverage for November 2014 is estimated to be about 11 percent. CPS coverage varies with age, sex, and race. Generally, coverage is larger for females than for males and larger for non-Blacks than for Blacks. This differential coverage is a general problem for most household-based surveys.
1The CPS weighting procedure partially corrects for bias from undercoverage, but biases may still be present when people who are missed by the survey differ from those interviewed in ways other than age, race, sex, Hispanic origin, and state of residence. How this weighting procedure affects other variables in the survey is not precisely known. All of these considerations affect comparisons across different surveys or data sources.
1A common measure of survey coverage is the coverage ratio, calculated as the estimated population before poststratification divided by the independent population control. Table 1 shows November 2014 CPS coverage ratios by age and sex for certain race and Hispanic groups. The CPS coverage ratios can exhibit some variability from month to month.
Table 1. CPS Coverage Ratios: November 2014 |
|||||||||||
|
Total |
White only |
Black only |
Residual race |
Hispanic |
||||||
Age group |
All people |
Male |
Female |
Male |
Female |
Male |
Female |
Male |
Female |
Male |
Female |
0-15 |
0.89 |
0.91 |
0.88 |
0.95 |
0.92 |
0.81 |
0.77 |
0.80 |
0.81 |
0.85 |
0.86 |
16-19 |
0.85 |
0.88 |
0.81 |
0.89 |
0.85 |
0.85 |
0.67 |
0.86 |
0.73 |
0.86 |
0.82 |
20-24 |
0.76 |
0.76 |
0.76 |
0.79 |
0.80 |
0.57 |
0.63 |
0.81 |
0.65 |
0.71 |
0.75 |
25-34 |
0.84 |
0.82 |
0.85 |
0.85 |
0.88 |
0.67 |
0.77 |
0.75 |
0.78 |
0.75 |
0.83 |
35-44 |
0.89 |
0.87 |
0.92 |
0.91 |
0.95 |
0.74 |
0.84 |
0.77 |
0.80 |
0.78 |
0.87 |
45-54 |
0.90 |
0.90 |
0.91 |
0.91 |
0.93 |
0.82 |
0.83 |
0.90 |
0.86 |
0.82 |
0.85 |
55-64 |
0.91 |
0.89 |
0.92 |
0.91 |
0.94 |
0.79 |
0.89 |
0.83 |
0.82 |
0.81 |
0.89 |
65+ |
0.96 |
0.96 |
0.95 |
0.97 |
0.96 |
0.89 |
0.96 |
0.83 |
0.84 |
0.82 |
0.85 |
15+ |
0.88 |
0.88 |
0.89 |
0.90 |
0.92 |
0.76 |
0.82 |
0.81 |
0.79 |
0.78 |
0.84 |
0+ |
0.89 |
0.88 |
0.89 |
0.91 |
0.92 |
0.77 |
0.80 |
0.81 |
0.80 |
0.80 |
0.85 |
Notes: (1) The Residual race group includes cases indicating a single race other than White or Black,
and cases indicating two or more races.
Hispanics may be any race. For a more detailed discussion on the use of parameters for
race and ethnicity, please see the “Generalized Variance Parameters” section.
1Comparability of Data. Data obtained from the CPS and other sources are not entirely comparable. This results from differences in interviewer training and experience and in differing survey processes. This is an example of nonsampling variability not reflected in the standard errors. Therefore, caution should be used when comparing results from different sources.
Data users should be careful when comparing the data from this microdata file, which reflects Census 2010-based controls, with microdata files from January 2003 through December 2011, which reflect 2000 census-based controls. Ideally, the same population controls should be used when comparing any estimates. In reality, the use of the same population controls is not practical when comparing trend data over a period of 10 to 20 years. Thus, when it is necessary to combine or compare data based on different controls or different designs, data users should be aware that changes in weighting controls or weighting procedures can create small differences between estimates. See the discussion following for information on comparing estimates derived from different controls or different sample designs.
Microdata files from previous years reflect the latest available census-based controls. Although the most recent change in population controls had relatively little impact on summary measures such as averages, medians, and percentage distributions, it did have a significant impact on levels. For example, use of Census 2010-based controls results in about a 0.2 percent increase from the 2000 census-based controls in the civilian noninstitutionalized population and in the number of families and households. Thus, estimates of levels for data collected in 2012 and later years will differ from those for earlier years by more than what could be attributed to actual changes in the population. These differences could be disproportionately greater for certain population subgroups than for the total population.
Users should also exercise caution because of changes caused by the phase-in of the Census 2000 files (see “Basic CPS”).4 During this time period, CPS data were collected from sample designs based on different censuses. Three features of the new CPS design have the potential of affecting published estimates: (1) the temporary disruption of the rotation pattern from August 2004 through June 2005 for a comparatively small portion of the sample, (2) the change in sample areas, and (3) the introduction of the new Core-Based Statistical Areas (formerly called metropolitan areas). Most of the known effect on estimates during and after the sample redesign will be the result of changing from 1990 to 2000 geographic definitions. Research has shown that the national-level estimates of the metropolitan and nonmetropolitan populations should not change appreciably because of the new sample design. However, users should still exercise caution when comparing metropolitan and nonmetropolitan estimates across years with a design change, especially at the state level.
Caution should also be used when comparing Hispanic estimates over time. No independent population control totals for people of Hispanic origin were used before 1985.
1A Nonsampling Error Warning. Since the full extent of the nonsampling error is unknown, one should be particularly careful when interpreting results based on small differences between estimates. The Census Bureau recommends that data users incorporate information about nonsampling errors into their analyses, as nonsampling error could impact the conclusions drawn from the results. Caution should also be used when interpreting results based on a relatively small number of cases. Summary measures (such as medians and percentage distributions) probably do not reveal useful information when computed on a subpopulation smaller than 75,000.
For additional information on nonsampling error including the possible impact on CPS
data when known, refer to references [2] and [3].
1Standard Errors and Their Use. 1The sample estimate and its standard error enable one to construct a confidence interval. A confidence interval is a range about a given estimate that has a specified probability of containing the average result of all possible samples. For example, if all possible samples were surveyed under essentially the same general conditions and using the same sample design, and if an estimate and its standard error were calculated from each sample, then approximately 90 percent of the intervals from 1.645 standard errors below the estimate to 1.645 standard errors above the estimate would include the average result of all possible samples.
1A particular confidence interval may or may not contain the average estimate derived from all possible samples, but one can say with specified confidence that the interval includes the average estimate calculated from all possible samples.
1Standard errors may also be used to perform hypothesis testing, a procedure for distinguishing between population parameters using sample estimates. The most common type of hypothesis is that the population parameters are different. An example of this would be comparing the percentage of men who were part-time workers to the percentage of women who were part-time workers.
1Tests may be performed at various levels of significance. A significance level is the probability of concluding that the characteristics are different when, in fact, they are the same. For example, to conclude that two characteristics are different at the 0.10 level of significance, the absolute value of the estimated difference between characteristics must be greater than or equal to 1.645 times the standard error of the difference.
1The Census Bureau uses 90-percent confidence intervals and 0.10 levels of significance to determine statistical validity. Consult standard statistical textbooks for alternative criteria.
1Estimating Standard Errors. The Census Bureau uses replication methods to estimate the standard errors of CPS estimates. These methods primarily measure the magnitude of sampling error. However, they do measure some effects of nonsampling error as well. They do not measure systematic biases in the data associated with nonsampling error. Bias is the average over all possible samples of the differences between the sample estimates and the true value.
There are two ways to calculate standard errors for the CPS microdata file on Voting and Registration. They are:
Direct estimates created from replicate weighting methods;
Generalized variance estimates created from generalized variance function parameters a and b.
While replicate weighting methods provide the most accurate variance estimates, this approach requires more computing resources and more expertise on the part of the user. The Generalized Variance Function (GVF) parameters provide a method of balancing accuracy with resource usage as well as a smoothing effect on standard error estimates across time. For more information on calculating direct estimates, see reference [4]. For more information on generalized variance estimates refer to the “Generalized Variance Parameters” section.
1Generalized Variance Parameters. While it is possible to compute and present an estimate of the standard error based on the survey data for each estimate in a report, there are a number of reasons why this is not done. A presentation of the individual standard errors would be of limited use, since one could not possibly predict all of the combinations of results that may be of interest to data users. Additionally, data users have access to CPS microdata files, and it is impossible to compute in advance the standard error for every estimate one might obtain from those data sets. Moreover, variance estimates are based on sample data and have variances of their own. Therefore, some methods of stabilizing these estimates of variance, for example, by generalizing or averaging over time, may be used to improve their reliability.
1Experience has shown that certain groups of estimates have similar relationships between their variances and expected values. Modeling or generalizing may provide more stable variance estimates by taking advantage of these similarities. The generalized variance function is a simple model that expresses the variance as a function of the expected value of the survey estimate. The parameters of the generalized variance function are estimated using direct replicate variances. These generalized variance parameters provide a relatively easy method to obtain approximate standard errors for numerous characteristics. In this source and accuracy statement, Table 3 provides the generalized variance parameters for labor force estimates, and Table 4 provides generalized variance parameters for characteristics from the November 2014 supplement. Tables 5 through 7 provide generalized variance parameters for U.S. states, divisions, and regions. Tables 8 through 10 provide factors and population controls to derive U.S. state, division, and regional parameters.
The basic CPS questionnaire records the race and ethnicity of each respondent. With respect to race, a respondent can be White, Black, Asian, American Indian and Alaskan Native (AIAN), Native Hawaiian and Other Pacific Islander (NHOPI), or combinations of two or more of the preceding. A respondent’s ethnicity can be Hispanic or non-Hispanic, regardless of race.
The generalized variance parameters to use in computing standard errors are dependent upon the race/ethnicity group of interest. The following table summarizes the relationship between the race/ethnicity group of interest and the generalized variance parameters to use in standard error calculations.
Table 2. Estimation Groups of Interest and Generalized Variance Parameters |
|
Race/ethnicity group of interest |
Generalized variance parameters to use in standard error calculations |
Total population |
Total or White |
White alone, White AOIC, or White non-Hispanic population |
Total or White |
Black alone, Black AOIC, or Black non-Hispanic population |
Black |
Asian alone, Asian AOIC, or Asian non-Hispanic population |
Asian, AIAN, NHOPI |
AIAN alone, AIAN AOIC, or AIAN non-Hispanic population |
|
NHOPI alone, NHOPI AOIC, or NHOPI non-Hispanic population |
|
Populations from other race groups |
Asian, AIAN, NHOPI |
Hispanic population |
Hispanic |
Two or more races – employment/unemployment and educational attainment characteristics |
Black |
Two or more races – all other characteristics |
Asian, AIAN, NHOPI |
Notes: (1) AIAN is American Indian and Alaska Native and NHOPI is Native Hawaiian and Other Pacific Islander.
AOIC is an abbreviation for alone or in combination. The AOIC population for a race group of interest includes people reporting only the race group of interest (alone) and people reporting multiple race categories including the race group of interest (in combination).
Hispanics may be any race.
Two or more races refers to the group of cases self-classified as having two or more races.
Standard Errors of Estimated Numbers. The approximate standard error, sx, of an estimated number from this microdata file can be obtained by using the formula:
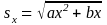 (1)
(1)
1Here x is the size of the estimate and a and b are the parameters in Table 3 or 4 associated with the particular type of characteristic. When calculating standard errors from cross-tabulations involving different characteristics, use the set of parameters for the characteristic that will give the largest standard error.
1Illustration 1
Suppose in November 2014 there were 4,627,000 unemployed men (ages 16 and up) in the civilian labor force. Use the appropriate parameters from Table 3 and Formula (1) to get
Illustration 1 |
|
Number of unemployed males in the civilian labor force (x) |
4,627,000 |
a parameter (a) |
-0.000031 |
b parameter (b) |
2,947 |
Standard error |
114,000 |
90-percent confidence interval |
4,439,000 to 4,815,000 |
The standard error is calculated as
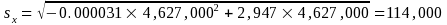
1The 90-percent confidence interval is calculated as 4,627,000 ± 1.645 × 114,000.
1A conclusion that the average estimate derived from all possible samples lies within a range computed in this way would be correct for roughly 90 percent of all possible samples.
1Standard Errors of Estimated Percentages. The reliability of an estimated percentage, computed using sample data for both numerator and denominator, depends on both the size of the percentage and its base. Estimated percentages are relatively more reliable than the corresponding estimates of the numerators of the percentages, particularly if the percentages are 50 percent or more. When the numerator and denominator of the percentage are in different categories, use the parameter from Table 3 or 4 as indicated by the numerator.
1The approximate standard error, sy,p, of an estimated percentage can be obtained by using the formula:
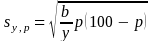 (2)
(2)
1Here y is the total number of people, families, households, or unrelated individuals in the base or denominator of the percentage, p is the percentage 100*x/y (0 ≤ p ≤ 100), and b is the parameter in Table 3 or 4 associated with the characteristic in the numerator of the percentage.
1Illustration 2
In November 2014, out of 239,106,000 people with at least an elementary school education, 38.6 percent reported voting. Use the appropriate parameter from Table 4 and formula (2) to get
Illustration 2 |
|
Percentage that reported voting (p) |
38.6 |
Base (y) |
239,106,000 |
b parameter (b) |
3,496 |
Standard error |
0.19 |
90-percent confidence interval |
38.3 to 38.9 |
1The standard error is calculated as
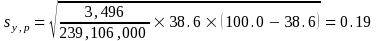
The 90-percent confidence interval for the estimated percentage of people with at least an elementary school education who reported voting is from 38.3 to 38.9 percent (i.e., 38.6 ± 1.645 × 0.19).
1Standard Errors of Estimated Differences. The standard error of the difference between two sample estimates is approximately equal to
 (3)
(3)
where sx1 and sx2 are the standard errors of the estimates, x1 and x2. The estimates can be numbers, percentages, ratios, etc. This will result in accurate estimates of the standard error of the same characteristic in two different areas, or for the difference between separate and uncorrelated characteristics in the same area. However, if there is a high positive (negative) correlation between the two characteristics, the formula will overestimate (underestimate) the true standard error.
1Illustration 3
The November 2014 supplement showed that out of 115,293,000 men who had at least an elementary school education, 42,987,000 or 37.3 percent had voted, and of the 123,813,000 women who had at least an elementary school education, 49,193,000 or 39.7 percent had voted. Use the appropriate parameters from Table 4 and Formulas (2) and (3) to get
Illustration 3 |
|||
|
Male (x1) |
Female (x2) |
Difference |
Percentage that had voted (p) |
37.3 |
39.7 |
2.4 |
Base (y) |
115,293,000 |
123,813,000 |
|
b parameter (b) |
3,496 |
3,496 |
|
Standard error |
0.27 |
0.26 |
0.37 |
90-percent confidence interval |
36.9 to 37.7 |
39.3 to 40.1 |
1.8 to 3.0 |
The standard error of the difference is calculated as
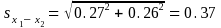
1The 90-percent confidence interval around the difference is calculated as 2.4 ± 1.645 × 0.37. Since this interval does not include zero, we can conclude with 90 percent confidence that the percentage of women with at least an elementary school education who voted is greater than the percentage of men with at least an elementary school education who voted.
Standard Errors for State, Division, and Region Estimates. Standard errors for state, division, and region estimates may be obtained by using the state, division, and region parameters. The state, division, and region parameters for Total or White population voting and registration estimates are included in Tables 5, 6, and 7. The state, division, and region parameters for other subpopulation groups are determined by multiplying the a and b parameters in Table 4 by the appropriate factor from Tables 8, 9, or 10. The state factors are contained in Table 8, the division factors in Table 9, and the region factors in Table 10. After determining the correct parameter, use the standard error formulas discussed earlier in the text to calculate standard error estimates.
1Illustration 4
About 5,419,000 people (35.5 percent) have completed at least a bachelor’s degree out of about 15,274,000 people aged 18 and over living in New York. Following the method mentioned above, obtain the needed state parameter by multiplying the parameter in Table 4 by the state factor in Table 8 for the state of interest. In this example, the educational attainment parameter for Total or White in New York is calculated as b = 2,530 × 1.19 = 3,011.
Use formula (2) with the new b parameter, 3,011, to get
Illustration 4 |
|
Percentage that reported voting (p) |
35.5 |
Base (y) |
15,274,000 |
b parameter (b) |
3,011 |
Standard error |
0.67 |
90-percent confidence interval |
34.4 to 36.6 |
Technical Assistance. If you require assistance or additional information, please contact the Demographic Statistical Methods Division via e-mail at dsmd.source.and.accuracy@census.gov.
11
Table 3. Parameters for Computation of Standard Errors for Labor Force Characteristics: November 2014 |
||
Characteristic |
a |
b |
|
|
|
Total or White |
|
|
|
|
|
Civilian labor force, employed |
-0.000013 |
2,481 |
Unemployed |
-0.000017 |
3,244 |
Not in labor force |
-0.000013 |
2,432 |
|
|
|
Civilian labor force, employed, not in labor force, and unemployed |
|
|
Men |
-0.000031 |
2,947 |
Women |
-0.000028 |
2,788 |
Both sexes, 16 to 19 years |
-0.000261 |
3,244 |
|
|
|
Black |
|
|
|
|
|
Civilian labor force, employed, not in labor force, and unemployed |
|
|
Total |
-0.000117 |
3,601 |
Men |
-0.000249 |
3,465 |
Women |
-0.000191 |
3,191 |
Both sexes, 16 to 19 years |
-0.001425 |
3,601 |
|
|
|
Asian, American Indian and Alaska Native, Native Hawaiian and Other Pacific Islander |
|
|
|
|
|
Civilian labor force, employed, not in labor force, and unemployed |
|
|
Total |
-0.000245 |
3,311 |
Men |
-0.000537 |
3,397 |
Women |
-0.000399 |
2,874 |
Both sexes, 16 to 19 years |
-0.004078 |
3,311 |
|
|
|
Hispanic, may be of any race |
|
|
|
|
|
Civilian labor force, employed, not in labor force, and unemployed |
|
|
Total |
-0.000087 |
3,316 |
Men |
-0.000172 |
3,276 |
Women |
-0.000158 |
3,001 |
Both sexes, 16 to 19 years |
-0.000909 |
3,316 |
|
|
|
|
|
|
Notes: (1) These parameters are to be applied to basic CPS monthly labor force estimates.
The Total or White, Black, and Asian, AIAN, NHOPI parameters are to be used for both alone and in combination race group estimates.
For nonmetropolitan characteristics, multiply the a and b parameters by 1.5. If the characteristic of interest is total state population, not subtotaled by race or ethnicity, the a and b parameters are zero.
For foreign-born and noncitizen characteristics for Total and White, the a and b parameters should be multiplied by 1.3. No adjustment is necessary for foreign-born and noncitizen characteristics for Black, Hispanic, and Asian, AIAN, NHOPI parameters.
For the groups self-classified as having two or more races, use the Asian, AIAN, NHOPI parameters for all employment characteristics.
Table 4. Parameters for Computation of Standard Errors for Voting and Registration Characteristics: November 2014 |
||||||||
Characteristics |
Total or White |
Black |
API, AIAN, NHOPI |
Hispanic |
||||
a |
b |
a |
b |
a |
b |
a |
b |
|
Voting, registration, reasons for not voting or registering (includes breakdowns by: Citizenship, Household relationship, Family heads by presence of children, Marital status, Duration of residence, Tenure, Education level, Family income of persons, (Occupation group) |
-0.000014 |
3,496 |
-0.000097 |
5,124 |
-0.000256 |
5,586 |
-0.000223 |
8,636 |
|
|
|
|
|
|
|
|
|
CHARACTERISTICS OF ALL PERSONS, VOTING AND NONVOTING |
||||||||
Marital Status |
-0.000018 |
5,564 |
-0.000113 |
7,993 |
-0.000268 |
7,993 |
-0.000245 |
13,471 |
Education of Persons |
-0.000010 |
2,530 |
-0.000053 |
2,861 |
-0.000102 |
2,310 |
-0.000073 |
3,259 |
Education of Family Head |
-0.000009 |
2,208 |
-0.000037 |
1,998 |
-0.000088 |
1,998 |
-0.000076 |
3,367 |
Persons by Family Income |
-0.000021 |
5,233 |
-0.000110 |
5,992 |
-0.000263 |
5,992 |
-0.000227 |
10,097 |
Duration of Residence, Tenure |
-0.000018 |
5,564 |
-0.000113 |
7,993 |
-0.000268 |
7,993 |
-0.000245 |
13,471 |
|
|
|
|
|
|
|
|
|
HOUSEHOLD RELATIONSHIPS, VOTING AND NONVOTING |
||||||||
Head, Spouse of Head |
-0.000009 |
2,208 |
-0.000037 |
1,998 |
-0.000088 |
1,998 |
-0.000076 |
3,367 |
Nonrelative or Other Relative of Head |
-0.000018 |
5,564 |
-0.000113 |
7,993 |
-0.000268 |
7,993 |
-0.000245 |
13,471 |
|
|
|
|
|
|
|
|
|
Notes: (1) These parameters are to be applied to the November 2014 Voting and Registration Supplement data.
AIAN is American Indian and Alaska Native and NHOPI is Native Hawaiian and Other Pacific Islander.
(3) Hispanics may be any race. For a more detailed discussion on the use of parameters for race and ethnicity, please see the “Generalized Variance Parameters” section.
(4) The Total or White, Black, and Asian, AIAN, NHOPI parameters are to be used for both alone and in combination race group estimates.
(5) For nonmetropolitan characteristics, multiply the a and b parameters by 1.5. If the characteristic of interest is total state population, not subtotaled by race or ethnicity, the a and b parameters are zero.
(6) For foreign-born and noncitizen characteristics for Total and White, the a and b parameters should be multiplied by 1.3. No adjustment is necessary for foreign-born and noncitizen characteristics for Black, Asian, AIAN, NHOPI, and Hispanic parameters.
(7) For the group self-classified as having two or more races, use the Asian, AIAN, NHOPI parameters for all characteristics except employment, unemployment, and educational attainment, in which case use Black parameters.
Table 5. Parameters for Computation of State Standard Errors: November 2014 |
||
State |
a |
b |
|
|
|
Alabama |
-0.000827 |
3,950 |
Alaska |
-0.000889 |
629 |
Arizona |
-0.000614 |
4,055 |
Arkansas |
-0.000873 |
2,552 |
California |
-0.000106 |
4,055 |
Colorado |
-0.000778 |
4,090 |
Connecticut |
-0.000865 |
3,076 |
Delaware |
-0.000874 |
804 |
District of Columbia |
-0.000961 |
629 |
Florida |
-0.000200 |
3,916 |
Georgia |
-0.000411 |
4,055 |
Hawaii |
-0.000848 |
1,154 |
Idaho |
-0.000869 |
1,398 |
Illinois |
-0.000319 |
4,055 |
Indiana |
-0.000611 |
3,985 |
Iowa |
-0.000887 |
2,727 |
Kansas |
-0.000996 |
2,832 |
Kentucky |
-0.000937 |
4,055 |
Louisiana |
-0.000814 |
3,706 |
Maine |
-0.001117 |
1,468 |
Maryland |
-0.000707 |
4,160 |
Massachusetts |
-0.000591 |
3,950 |
Michigan |
-0.000410 |
4,020 |
Minnesota |
-0.000749 |
4,055 |
Mississippi |
-0.000848 |
2,482 |
Missouri |
-0.000691 |
4,125 |
Montana |
-0.000761 |
769 |
Nebraska |
-0.000959 |
1,783 |
Nevada |
-0.000902 |
2,517 |
New Hampshire |
-0.000935 |
1,224 |
New Jersey |
-0.000454 |
4,020 |
New Mexico |
-0.000751 |
1,538 |
New York |
-0.000213 |
4,160 |
North Carolina |
-0.000423 |
4,125 |
|
|
|
Notes: (1) These parameters are for use with state level voting and registration estimates for the
Total or White population. For state level estimates of subpopulation groups, please
use the factors provided in Table 8.
Table 5. Parameters for Computation of State Standard Errors: November 2014 |
||
State |
a |
b |
|
|
|
North Dakota |
-0.000853 |
629 |
Ohio |
-0.000351 |
4,020 |
Oklahoma |
-0.000979 |
3,741 |
Oregon |
-0.000944 |
3,706 |
Pennsylvania |
-0.000321 |
4,055 |
Rhode Island |
-0.000943 |
979 |
South Carolina |
-0.000828 |
3,916 |
South Dakota |
-0.000955 |
804 |
Tennessee |
-0.000618 |
3,985 |
Texas |
-0.000155 |
4,090 |
Utah |
-0.000609 |
1,783 |
Vermont |
-0.001126 |
699 |
Virginia |
-0.000511 |
4,160 |
Washington |
-0.000589 |
4,090 |
West Virginia |
-0.000958 |
1,748 |
Wisconsin |
-0.000712 |
4,055 |
Wyoming |
-0.000964 |
559 |
|
|
|
Notes: (1) These parameters are for use with state level voting and registration estimates for the
Total or White population. For state level estimates of subpopulation groups, please
use the factors provided in Table 8.
-
Table 6. Parameters for Computation of Division Standard Errors: November 2014
Division
a
b
New England
-0.000199
2,891
Middle Atlantic
-0.000100
4,090
East North Central
-0.000087
4,020
West North Central
-0.000157
3,251
South Atlantic
-0.000063
3,881
East South Central
-0.000204
3,776
West South Central
-0.000103
3,881
Mountain
-0.000129
2,937
Pacific
-0.000077
3,916
Notes: (1) These parameters are for use with census division level voting and registration estimates for the
Total or White population. For census division level estimates of subpopulation groups, please
use the factors provided in Table 9.
-
Table 7. Parameters for Computation of Region Standard Errors: November 2014
Region
a
b
Northeast
-0.000068
3,776
Midwest
-0.000057
3,811
South
-0.000033
3,881
West
-0.000049
3,601
All Except South
-0.000019
3,722
Notes: (1) These parameters are for use with census region level voting and registration estimates for the
Total or White population. For census region level estimates of subpopulation groups, please
use the factors provided in Table 10.
Table 8. Factors and Populations for State Parameters: November 2014 |
||||||
State |
Factor |
Population |
State |
Factor |
Population |
|
|
|
|
|
|
|
|
Alabama |
1.13 |
4,778,589 |
Montana |
0.22 |
1,010,941 |
|
Alaska |
0.18 |
707,473 |
Nebraska |
0.51 |
1,859,040 |
|
Arizona |
1.16 |
6,604,881 |
Nevada |
0.72 |
2,790,964 |
|
Arkansas |
0.73 |
2,924,361 |
New Hampshire |
0.35 |
1,309,094 |
|
California |
1.16 |
38,217,301 |
New Jersey |
1.15 |
8,853,654 |
|
Colorado |
1.17 |
5,258,711 |
New Mexico |
0.44 |
2,047,286 |
|
Connecticut |
0.88 |
3,556,962 |
New York |
1.19 |
19,534,145 |
|
Delaware |
0.23 |
919,838 |
North Carolina |
1.18 |
9,746,855 |
|
District of Columbia |
0.18 |
654,435 |
North Dakota |
0.18 |
737,421 |
|
Florida |
1.12 |
19,539,588 |
Ohio |
1.15 |
11,443,291 |
|
Georgia |
1.16 |
9,873,809 |
Oklahoma |
1.07 |
3,820,242 |
|
Hawaii |
0.33 |
1,360,767 |
Oregon |
1.06 |
3,926,286 |
|
Idaho |
0.40 |
1,609,462 |
Pennsylvania |
1.16 |
12,620,505 |
|
Illinois |
1.16 |
12,727,899 |
Rhode Island |
0.28 |
1,038,602 |
|
Indiana |
1.14 |
6,522,417 |
South Carolina |
1.12 |
4,729,529 |
|
Iowa |
0.78 |
3,074,573 |
South Dakota |
0.23 |
841,499 |
|
Kansas |
0.81 |
2,843,999 |
Tennessee |
1.14 |
6,447,160 |
|
Kentucky |
1.16 |
4,328,279 |
Texas |
1.17 |
26,430,362 |
|
Louisiana |
1.06 |
4,552,198 |
Utah |
0.51 |
2,929,778 |
|
Maine |
0.42 |
1,314,166 |
Vermont |
0.20 |
620,531 |
|
Maryland |
1.19 |
5,887,561 |
Virginia |
1.19 |
8,134,440 |
|
Massachusetts |
1.13 |
6,681,419 |
Washington |
1.17 |
6,948,331 |
|
Michigan |
1.15 |
9,812,021 |
West Virginia |
0.50 |
1,825,362 |
|
Minnesota |
1.16 |
5,416,237 |
Wisconsin |
1.16 |
5,696,544 |
|
Mississippi |
0.71 |
2,926,656 |
Wyoming |
0.16 |
579,880 |
|
Missouri |
1.18 |
5,966,362 |
|
|
|
|
Notes: (1) These factors are for use with state level voting and registration estimates for subpopulation groups.
The state population counts in this table are for the 0+ population.
(3) For foreign-born and noncitizen characteristics for Total and White, the a and b parameters should be multiplied by 1.3. No adjustment is necessary for foreign-born and noncitizen characteristics for Blacks, API, and Hispanics.
-
Table 9. Factors and Populations for Division Parameters: November 2014
Division
Factor
Population
New England
0.83
14,520,774
Middle Atlantic
1.17
41,008,304
East North Central
1.15
46,202,172
West North Central
0.93
20,739,131
South Atlantic
1.11
61,311,417
East South Central
1.08
18,480,684
West South Central
1.11
37,727,163
Mountain
0.84
22,831,903
Pacific
1.12
51,160,158
Notes: (1) These factors are for use with census division level voting and registration estimates for
subpopulation groups.
The census division population counts in this table are for the 0+ population.
(3) For foreign-born and noncitizen characteristics for Total and White, the a and b parameters should be multiplied by 1.3. No adjustment is necessary for foreign-born and noncitizen characteristics for Blacks, API, and Hispanics.
Table 10. Factors and Populations for Region Parameters: November 2014 |
||
Region |
Factor |
Population |
|
|
|
Northeast |
1.08 |
55,529,078 |
Midwest |
1.09 |
66,941,303 |
South |
1.11 |
117,519,264 |
West |
1.03 |
73,992,061 |
|
|
|
All Except South |
1.06 |
196,462,442
|
|
|
|
Notes: (1) These factors are for use with census region level voting and registration estimates for
subpopulation groups.
The census region population counts in this table are for the 0+ population.
(3) For foreign-born and noncitizen characteristics for Total and White, the a and b parameters should be multiplied by 1.3. No adjustment is necessary for foreign-born and noncitizen characteristics for Blacks, API, and Hispanics.
REFERENCES
[1] Bureau of Labor Statistics, April 2014, “Redesign of the Sample for the Current Population Survey.” http://www.bls.gov/cps/sample_redesign_2014.pdf
[2] U.S. Census Bureau. 2006. Current Population Survey: Design and Methodology. Technical Paper 66. Washington, DC: Government Printing Office. (http://www.census.gov/prod/2006pubs/tp-66.pdf)
[3] Brooks, C.A. and Bailar, B.A. 1978. Statistical Policy Working Paper 3 - An Error
Profile: Employment as Measured by the Current Population Survey. Subcommittee on
Nonsampling Errors, Federal Committee on Statistical Methodology, U.S. Department of
Commerce, Washington, DC. (http://www.fcsm.gov/working-papers/spp.html)
[4] U.S. Census Bureau, July 15, 2009, “Estimating ASEC Variances with Replicate Weights Part I: Instructions for Using the ASEC Public Use Replicate Weight File to Create ASEC Variance Estimates.”
http://usa.ipums.org/usa/repwt/Use_of_the_Public_Use_Replicate_Weight_File_final_PR.doc
Accessed: January 5, 2012
1 For detailed information on the 2000 sample redesign, please see reference [1].
2 The PSUs correspond to substate areas (i.e., counties or groups of counties) that are geographically contiguous.
3 For further information on CATI and CAPI and the eligibility criteria, please see reference [2].
4 The phase-in process using the 2010 Census files will begin April 2014.
| File Type | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
| Author | herbs002 |
| File Modified | 0000-00-00 |
| File Created | 2021-01-23 |
© 2026 OMB.report | Privacy Policy