Part B NCS 2015 01-26-2015
Part B NCS 2015 01-26-2015.docx
National Compensation Survey
OMB: 1220-0164
Supporting Statement – 01/22/2015
National Compensation Survey (NCS)
B. Collection of Information Employing Statistical Methods
For detailed technical materials on the sample allocation, selection, and estimation methods as well as other related statistical procedures see the BLS Handbook of Methods, BLS technical reports, and ASA papers listed in the references section. The following is a brief summary of the primary statistical features of the NCS.
As described in Sections 1 – 3 of this document, the redesigned NCS sample is selected using a 2-stage stratified design with probability proportional to employment sampling at each stage. The first stage of sample selection is a probability sample of establishments within pre-defined geographic areas of interest, and the second stage of sample selection is a probability sample of jobs within sampled establishments. The NCS uses 24 geographic areas, one for each of the 15 largest metropolitan areas by employment and one for the remainder of each Census Division. Data from all sampled establishments are used to produce the cost and benefit products.
1a. Universe
The NCS measures employee compensation in the form of wages and benefits for detailed geographic areas, industries, and occupations as well as national level estimates by industry and occupation. The universe for this survey consists of the Quarterly Contribution Reports (QCR) filed by employers subject to State Unemployment Insurance (UI) laws. The BLS receives these QCR for the Quarterly Census of Employment and Wages (QCEW) Program from the 50 States, the District of Columbia, Puerto Rico, and the U.S. Virgin Islands. The QCEW data, which are compiled for each calendar quarter, provide a comprehensive business name and address file with employment, wage, detailed geography (i.e., county), and industry information at the six-digit North American Industry Classification System (NAICS) level. This information is provided for over nine million business establishments that are required to pay for unemployment insurance, most of which are in the scope of this survey.
Data on the duties and responsibilities of a sample of jobs will be collected in all sample establishments.
All of NCS’s 11,400 sample establishments are collected quarterly for the employment costs and benefits participation and plan provisions.
1b. Sample
Stratification, Sample Allocation, and Sample Selection
In FY 2012, the NCS began selecting the sample using a 2-stage stratified design with probability proportional to employment sampling at each stage. The first stage of sample selection is a probability sample of establishments within pre-defined geographic areas of interest, and the second stage of sample selection is a probability sample of jobs within sampled establishments. For more information on the sample design for private industry establishments, see the ASA paper by Ferguson et al titled, “Update on the Evaluation of Sample Design Issues in the National Compensation Survey” (Attachment 1). For more information on the sample design for State and local government businesses, see the ASA paper by Ferguson et al titled, “State and Local Government Sample Design for the National Compensation Survey” (Attachment 2).
Each sample of establishments is drawn by first stratifying the establishment sampling frame by defined geographic area of interest, industry and ownership. The industry strata for both private industry and for State and local government samples are shown below (North American Industry Classification System - NAICS-based). The 24 geographic areas of interest for the NCS appear in the third table below.
NCS Industry Stratification for Private Establishment Samples
Aggregate Industry |
Detailed Industry |
Included NAICS Codes |
Establishments in Frame |
Sample Size* |
Education |
Educational Services (Rest of) |
61 (excl 6111-6113) |
78,008 |
60 |
Education |
Elementary and Secondary Schools |
6111 |
16,899 |
86 |
Education |
Junior Colleges, Colleges and Universities |
6112, 6113 |
8,023 |
274 |
Finance, Insurance and Real Estate |
Finance (Rest of) |
52 (excl 524) |
279,462 |
950 |
Finance, Insurance and Real Estate |
Insurance |
524 |
185,133 |
581 |
Finance, Insurance and Real Estate |
Real Estate, Renting, Leasing |
53 |
349,578 |
213 |
Goods Producing |
Mining |
21 |
34,579 |
84 |
Goods Producing |
Construction |
23 |
744,370 |
913 |
Goods Producing |
Manufacturing |
31-33 |
334,610 |
1074 |
Health Care, including Hospitals and Nursing Care |
Healthcare, Social Assistance (Rest of) |
62 (excl 622, 623) |
1,230,175 |
186 |
Health Care, including Hospitals and Nursing Care |
Hospitals |
622 |
8,419 |
254 |
Health Care, including Hospitals and Nursing Care |
Nursing and Residential Care Facilities |
623 |
72,659 |
387 |
Service Providing |
Utilities |
22 |
17,130 |
122 |
Service Providing |
Wholesale Trade |
42 |
619,782 |
703 |
Service Providing |
Retail Trade |
44-45 |
1,031,277 |
1446 |
Service Providing |
Transportation and Warehousing |
48-49 |
225,026 |
316 |
Service Providing |
Information |
51 |
143,541 |
367 |
Service Providing |
Professional, Scientific, Technical |
54 |
1,075,999 |
411 |
Service Providing |
Management of Companies and Enterprises |
55 |
58,245 |
71 |
Service Providing |
Admin., Support, Waste Management |
56 |
485,943 |
455 |
Service Providing |
Arts, Entertainment, Recreation |
71 |
127,658 |
105 |
Service Providing |
Accommodation and Food Services |
72 |
647,059 |
394 |
Service Providing |
Other Services (excl Public Administration) |
81 (excl 814) |
563,765 |
352 |
* The sample size is the total three-year sample size allocated to each industry. Approximately one-third of these units will be initiated each year.
NCS Industry Stratification for State and Local Government Samples
Aggregate Industry |
Detailed Industry |
Included NAICS Codes |
Establishments in Frame |
Sample Size |
Education |
Elementary and Secondary Education |
6111 |
61,939 |
631 |
Education |
Colleges and Universities |
6112, 6113 |
7,457 |
205 |
Education |
Rest of Education |
61 excl 6111-6113 |
1,256 |
6 |
Financial Activities |
Other Service-providing - Part A |
52-53 |
244 |
24 |
Goods Producing |
Goods-Producing |
21, 23, 31-33 |
6,349 |
25 |
Health Care, including Hospitals and Nursing Care |
Hospitals |
622 |
2,571 |
83 |
Health Care, including Hospitals and Nursing Care |
Nursing Homes |
623 |
2,100 |
16 |
Health Care, including Hospitals and Nursing Care |
Rest of Health |
62, excl 622-623 |
8,490 |
28 |
Service Providing |
Trade, Transportation, and Utilities |
42, 44-45, 48-49, 22 |
12,847 |
49 |
Service Providing |
Public Administration |
92 excl 928 |
108,358 |
472 |
Service Providing |
Other Service-providing - Part B |
51, 54-56, 71-72, 81 excl 814 |
20,430 |
57 |
24 Geographic Areas for the NCS Sample Design
-
Atlanta--Athens-Clarke County--Sandy Springs, GA CSA
Boston-Worcester-Providence, MA-RI-NH-CT CSA
Chicago-Naperville, IL-IN-WI CSA
Dallas-Fort Worth, TX-OK CSA
Detroit-Warren-Ann Arbor, MI CSA
Houston-The Woodlands, TX CSA
Los Angeles-Long Beach, CA CSA
Minneapolis-St. Paul, MN-WI CSA
New York-Newark, NY-NJ-CT-PA CSA
Philadelphia-Reading-Camden, PA-NJ-DE-MD CSA
San Jose-San Francisco-Oakland, CA CSA
Seattle-Tacoma, WA CSA
Washington-Baltimore-Arlington, DC-MD-VA-WV-PA CSA
Miami-Fort Lauderdale-West Palm Beach, FL MSA
Phoenix-Mesa-Scottsdale, AZ MSA
Rest of New England Census Division (excl. areas above)
Rest of Middle Atlantic Census Division (excl. areas above)
Rest of East South Central Census Division (excl. areas above)
Rest of South Atlantic Census Division (excl. areas above)
Rest of North Central Census Division (excl. areas above)
Rest of West North Central Census Division (excl. areas above)
Rest of West South Central Census Division (excl. areas above)
Rest of Mountain Census Division (excl. areas above)
Rest of Pacific Census Division (excl. areas above)
* The above areas are based on the 2010 Decennial Census data which was released by the Census Bureau in February of 2013. NCS began using the above definitions with the State and Local Government sample selected in FY2015 which will begin collection in June 2015. The first private sample using the above definitions will be selected in FY 2016 and begin collection in June 2016. NCS Samples prior to FY2015 were selected using the area definitions defined by the 2000 Census released by the Census Bureau in 2003.
After the sample of establishments is drawn, jobs are selected in each sampled establishment. The number of jobs selected in a private establishment ranges from 4 to 8 depending on the total number of employees in the establishment, except for aircraft manufacturing establishments and establishments with fewer than 4 workers. In governments, the number of jobs selected ranges from 4 to 20, except for establishments with fewer than 4 workers. In aircraft manufacturing, the number of jobs selected ranges from 4 for establishments with fewer than 50 workers to 32 for establishments with 10,000 or more workers, unless the establishment has fewer than 4 workers. In establishments with fewer than 4 workers, the number of jobs selected equals the number of workers. The probability of a job being selected is proportionate to its employment within the establishment.
Scope - The NCS sample is selected from the populations as defined above.
Sample Allocation — The total NCS sample consists of approximately 11,400 establishments. The private portion of this sample, approximately 9,800 establishments, is allocated based on strata defined by the survey’s 24 geographic areas and five aggregate industries. The government portion of this sample, approximately 1,600 establishments, is also allocated based on strata defined by the survey’s 24 geographic areas and five aggregate industries, although the detailed industries for governments are different than those for private industry. Self-representing, certainty establishments are assigned a sampling weight of 1.00, and non-certainty establishments are assigned a sampling weight equal to the inverse of their selection probability.
For private industry samples, NCS computes detailed allocations and identifies multi-year certainty establishments once every three years under the three-year rotation cycle. If budget or resource levels change significantly, allocation will be recomputed, multi-year certainties will be re-selected, and a new three-year rotation will begin. This section will first describe the process for allocating sample sizes and identifying the multi-year certainty establishments followed by the proposed methods for when these processes are not executed for a specified sample.
The sample allocation process starts with a total budgeted sample size. The NCS will use targeted percentages across industries along with the frame data to determine how to distribute the sample units among the sampling cells for private industry samples. Due to the small sample size of the NCS for the private non-aircraft manufacturing allocation, NCS uses a five aggregate-industry stratum allocation with a modified measure of size within each of the 23 detailed industries. This adjustment to the measure of size (MOS) allows fewer strata but controls the number of units needed in the twenty-three detailed industries for which the NCS wants to publish private industry estimates.
The total three-year NCS private non-aircraft manufacturing sample size is first allocated to the five aggregate-industry strata. The size of each stratum is calculated so that the distribution of the new sample mirrors the desired distribution of the sample in order to maximize the ability to meet publication goals. Next, each of the five aggregate stratum allocations is divided among the 24 geographic areas in proportion to the total adjusted employment of the frame units in the areas, resulting in 120 initial area-industry cell allocations. The MOS of a frame unit is the product of the unit’s adjusted employment and an adjustment factor that is used to maintain the current distribution of the sample among the 23 detailed NCS industries.
Multi-year private industry certainty units are identified using the initial cell allocations and the adjusted MOS. Each initial area-industry cell allocation is then reduced by the number of certainty units in the cell to create 120 non-certainty area-industry cell allocations. The MOS adjustment factors are recalculated to exclude the certainty units. Finally, the non-certainty allocations are divided among the three years of the sample design by distributing the non-certainty sample sizes across each of the three years. This distribution is done by dividing each size by three and assigning the integer portion of the result to each of the three years. The remainder is assigned to the appropriate number of years, one establishment at a time, in a manner that allows each annual selected sample to be the same size and the size for each sampling cell to vary by no more than one from year to year.
Under normal processing, private industry sample allocation and identification of multi-year private certainty units are executed once every three years. During years when prior year allocations and multi-year certainties are being used, the most recently identified set of multi-year certainty establishments are removed from the frame for operational purposes and added to the final selected sample. This ensures that each sample group represents the entire frame. The most recent non-certainty allocations and the sample frame without the multi-year certainties are used to compute the final measure of size adjustment factor and to set the non-certainty sample size for each of the 120 area-industry sampling cells.
A sample of private aircraft manufacturing establishments is selected once every three years at the same time that we begin a new three-year rotation for the rest of private industry. Measures of size are set for these establishments in the same manner as is done for the other private industry establishments, except that there is no adjustment for detailed industries within this group.
A sample of State and local government establishments is selected once every ten years, between two of the three year rotations for private industry establishments. The public sector allocation process starts with the total budgeted sample size. First, one establishment is allocated to each of the 120 sampling cells. The remaining total sample size is then allocated to the five aggregate industry strata in proportion to the total employment within each industry. Finally, each of the five aggregate stratum allocations is divided among the 24 geographic areas in proportion to the total employment of the frame units in the areas, resulting in 120 area-industry cell allocations.
State and local government certainty units are identified using the initial cell allocations and the establishment MOS. When an establishment MOS is greater than the total employment in the cell divided by the initial cell allocation for the cell, the public sector establishment is flagged as a certainty unit and the remaining cell allocation is reduced by the number of certainty selections. This identification process is repeated until no more certainty units exist in any cell. Each initial area-industry cell allocation is then reduced by the number of certainty units in the cell to create 120 non-certainty area-industry cell allocations.
Sample Selection - Under this design, NCS selects an independent non-certainty sample of establishments every year within each of the five aggregate industry and 24 geographic area sampling cells. Within each of the sampling cells, units are sorted by detailed industry (23 for private and 10 for public sector), final adjusted MOS, and establishment identification number. The selection process follows a systematic Probability Proportionate to Size (PPS) approach where the measure of size includes the adjustment factor as defined in the allocation section. The private industry multi-year certainty units identified in the previous step are added to each private industry non-certainty sample to form the entire establishment sample.
Sample weights are assigned to each of the selected non-certainty establishments in the sample to represent the non-certainty portion of the frame. Units selected as certainty are self-representing and will carry a sample weight of one. The sample weight for the non-certainty units is the inverse of the probability of selection.
2a. Sample Design
Sample Rotation - Collection of the first private industry sample (including a sample of aircraft manufacturing establishments) under the national based design began in the spring of 2012. Starting in the spring of 2013, NCS began initiating the second private industry sample. The third private industry sample began initiation in the spring of 2014, and will complete the first rotation of private industry establishments under this sample design. For the State and local government sectors, a full sample is selected approximately every 10 years. The first State and local government sector sample under this new national design will begin initiation collection in the spring of 2015. After a 15 month initiation period and one quarter for base period wage and benefit cost collection, each sample will be added to the set of samples used in NCS estimates for the first time. As a new sample is added to the NCS estimates, the oldest sample from the same sector of the economy (private, aircraft manufacturing, or public) will be rotated out of the survey. All sampled establishments are used to support the production of all NCS product lines although only the most recently initiated sample is used to produce the detailed benefits estimates each year.
All sample units, private, State and local government, are assigned to one of four collection panels for initiation. Once a sample of establishments is selected and collection panels have been assigned, BLS Regional Office employees review and refine the sample before collection begins. As part of this refinement process, establishments may be moved from one collection panel to another to coordinate initiation with more than one establishment and/or to reduce travel costs associated with initiation efforts. Establishments are initiated over a fifteen month period with one collection panel required to be completed every three months after an initial 3 month detailed refinement period. Once initiated, a unit is then updated quarterly until it rotates out of the design. No newly initiated establishment is used in the NCS estimates until the entire sample has been initiated and updated for a common/base quarter. During this base quarter, data for the newly initiated sample as well as the prior sample is updated. After the base quarter is completed, the entire sample is added to the data available for estimation while the oldest sample in estimation is dropped from further updates and inclusion in the estimates.
Sample Replacement Scheme
Each year, the NCS selects a new sample of private sector establishments from the most recent available frame data. A new sample of jobs is selected within each private establishment at least once every 3 years (10 years for government) as the establishment is initiated into the survey process. The entire private NCS sample is completely replaced over a three year period on a rotational basis.
The primary objectives of the replacement scheme are to reduce the reporting burden of individual establishments by rotating units out of the sample and to insure that the establishment sample is representative of the universe it is designed to cover over time.
A timeline for the NCS sample replacement scheme for the private industry scope is provided below.
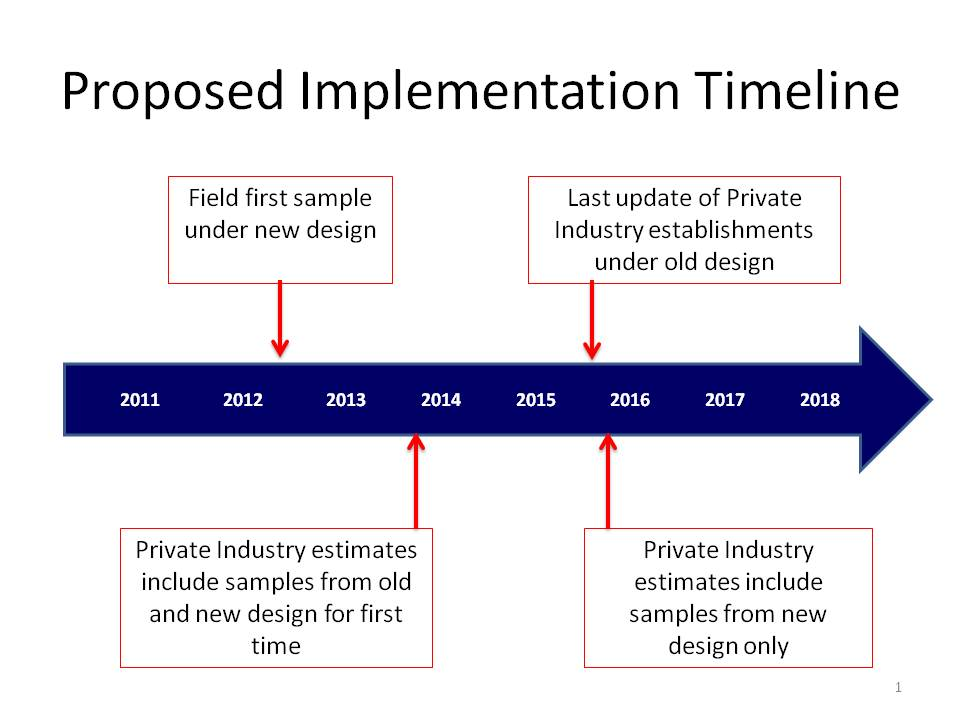
2b. Estimation Procedure
The survey produces level estimates, such as average earnings of service workers, and indexes. The estimation procedures for the earnings and index estimates are described below. The Index procedure also includes seasonal adjustment. Note that both of these procedures involve weighting the data from each employee in the sampled job by the final weight.
The final weights include the initial sample weights, adjustments to the initial sample weights, two types of adjustments for non-response, and benchmarking. The initial sample weight for a job in a particular establishment reflects the probability of selecting a particular establishment within one of the pre-defined geographic areas and the probability of selecting a particular job within the selected establishment. Adjustments to the initial weights are done when data are collected for more or less than the sampled establishment. This may be due to establishment mergers, splits, or the inability of respondents to provide the requested data for the sampled establishment. The two types of adjustments for non-response include adjustment for establishment refusal to participate in the survey and adjustment for respondent refusal to provide data for a particular job.
Benchmarking, or post-stratification, is the process of adjusting the weight of each establishment in the survey to match the distribution of employment by industry at the reference period. Because the sample of establishments used to collect NCS data was chosen over a period of several years, establishment weights reflect their employment when selected. For outputs other than the ECI, the benchmark process updates that weight based on current employment. For the ECI, the benchmark process updates that weight based on the employment during the publication base period. For more details about the NCS benchmarking procedures, see the BLS Handbook listed in the references below (Section 6).
The estimation procedure for level estimates uses the benchmark weight, which is the product of the weights, as described in the paragraph above. See Chapter 8 of the BLS Handbook of Methods (available on the BLS Internet at http://www.bls.gov/opub/hom/pdf/homch8.pdf) for an explanation of the estimation procedures for Employer Costs for Employee Compensation estimates and for Benefit Incidence and Provisions estimates.
The index computation involves the standard formula for Laspeyres fixed-employment-weighted index, modified by the special statistical conditions that apply to the NCS. An index for a benefit derived from the NCS data is simply a weighted average of the cumulative average benefit costs changes within each estimation cell, with base-period benefit bills as the fixed weights for each cell. This discussion focuses on the ECI measures of benefit cost changes, but indexes of changes in compensation and wages are computed in essentially the same fashion.
The simplified formula is:
Numerator
=
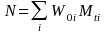
Denominator
=
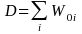
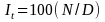
where:
i = estimation cell
t = time
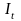 =
the index at time t
=
the index at time t
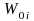 =
the estimated base-period benefit bill for the ith
estimation cell. The benefit bill is the average benefit cost of
workers in the cell times the number of workers represented by the
cell.
=
the estimated base-period benefit bill for the ith
estimation cell. The benefit bill is the average benefit cost of
workers in the cell times the number of workers represented by the
cell.
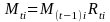 =
the cumulative average benefit cost
=
the cumulative average benefit cost
change in the ith estimation cell from time 0 (base period) to time t (current quarter).
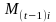 =
the cumulative average benefit cost change in the ith
estimation cell from time 0 (base period) to time t-1 (prior
quarter).
=
the cumulative average benefit cost change in the ith
estimation cell from time 0 (base period) to time t-1 (prior
quarter).
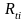 is
the ratio of the current quarter weighted average benefit cost in the
cell to the prior quarter weighted average benefit cost in the cell,
both calculated in the current quarter using matched
establishment/occupation observations.
is
the ratio of the current quarter weighted average benefit cost in the
cell to the prior quarter weighted average benefit cost in the cell,
both calculated in the current quarter using matched
establishment/occupation observations.
The estimation cell is defined on the basis of ownership/industry/major occupation group. For the public sector, separate cells are identified for State and for local governments. Industries as broad as “public administration” and as narrow as “colleges and universities” are treated as separate estimation cell industries. For example, one estimation cell is identified as State government/public administration/clerical workers.
The index computations for the occupation and industry groups follow the same procedures as those for all overall indexes except for the summation. The bills for the occupational groups are summed across industries for each group; the bills for the industry divisions are summed across occupational groups for each industry division.
Computational procedures for the regional, union/non-union, and metropolitan/non-metropolitan measures of change differ from those of the “national” indexes because the current sample is not large enough to hold constant the benefits bills at the level of detail. For these “non-national” series, each quarter the prevailing distribution in the sample between, for example, union and non-union within each industry/occupation cell, is used to apportion the prior quarter benefits bill in that cell between the union and non-union series. The portion of the benefits bill assigned to the union sector is then moved by the percentage change in the union earnings in the cell. The same is done for the non-union sector. Thus, the relative importance of the union sector in each cell is not held constant over time. Since the relative weights of the region, the union, and the metropolitan area sub-cells are allowed to vary over time, the non-national series are not fixed base period Laspeyres indexes; rather, these are similar to chain linked Laspeyres indexes.
Seasonal Adjustment
Current seasonally adjusted estimates are published in the ECI News Release and historical listing. Each year at the end of the December ECI quarterly production, seasonal adjustment revision is conducted, including revisions to seasonal factors and revisions to historical indexes and 3-month percent changes for the past 5 years. Due to seasonal adjustment revision, the set of published seasonally adjusted series is subject to change each year, as series that are not seasonal are not shown in the seasonally adjusted estimate tables and series that are newly seasonal are added to the tables. Seasonal factors for the coming year are posted on the BLS website at http://www.bls.gov/ncs/ect/ectsfact.htm. Revisions of historical seasonally adjusted data for the most recent five years also appear within the article referenced by the website.
The ECI series are seasonally adjusted using either the direct or indirect seasonal adjustment method. Indexes at comparatively low levels of aggregation, such as the construction wage index, are adjusted by the direct method; that is, dividing the index by its seasonal factor. Seasonal factors are derived using X-12 ARIMA (Auto-Regressive Integrated Moving Average), a seasonal adjustment program developed by the Census Bureau, as an extension of the standard X-11 method. For more information on X-12 ARIMA see the Census website at http://www.census.gov/srd/www/x12a/. Most of the higher level aggregate indexes are seasonally adjusted by the indirect method, a weighted sum of seasonally adjusted component indexes, where the weights sum to 1.0. For example, the civilian, State and local governments, private industry, goods producing, manufacturing, and service providing series are derived by the indirect seasonal adjustment method.
For more details about the NCS seasonal adjustment procedures, see the BLS Handbook listed in the references below (Section 6).
2c. Reliability
The estimation of sample variances for the NCS survey is accomplished through the method of Balanced Half Samples (BHS). This replication technique uses half samples of the original sample and calculates estimates using those sub-samples. The replicate weights in both half-samples are modified using Fay’s method of perturbation. The sample variance is calculated by measuring the variability of the estimates made from these sub-samples. For a detailed mathematical presentation of this method, see the BLS Handbook of Methods listed in the references.
Before estimates of these characteristics are released to the public, they are first screened to ensure that they do not violate the BLS confidentiality pledge. A promise is made to each private industry respondent and those government sector respondents who request confidentiality, that BLS will not release its reported data to the public in a manner which would allow others to identify the establishment, firm, or enterprise.
Measuring the Quality of the Estimates
The two basic sources of error in the estimates are bias and variance. Bias is the amount by which estimates systematically do not reflect the characteristics of the entire population. Many of the components of bias can be categorized as either response or non-response bias.
Response bias occurs when respondents’ answers systematically differ in the same direction from the correct values. For example, this occurs when respondents incorrectly indicate no change in benefits costs when benefits costs actually increased. Another possibility of having response bias is when data are collected for a unit other than the sampled unit. Response bias can be measured by using a re-interview survey. Properly designed and implemented, this can also indicate where improvements are needed and how to make these improvements. The NCS has a Technical Re-interview Program (TRP) that does a records check of a sample of each field economist’s schedules of collected data. TRP is a part of the overall review process. TRP verifies directly with respondents a sample of elements originally collected by the field economist. The results are reviewed for adherence to NCS collection procedures. Although not explicitly used to measure bias, this program allows the NCS to identify procedures that are being misunderstood and to make improvements in the NCS Data Collection Manual and training program.
Non-response bias is the amount by which estimates obtained do not properly reflect the characteristics of non-respondents. This bias occurs when non-responding establishments have earnings and benefit levels and movements that are different from those of responding establishments. Non-response bias is being addressed by continuous efforts to reduce the amount of non-response. NCS is analyzing the extent of non-response bias using administrative data from the survey frame. The results from initial analysis are documented in the 2006 ASA Proceedings of Survey Research Methods Section1. A follow-up study from 2008 is also listed in the references. Details regarding adjustment for non-response and current non-response bias research are provided in Section 3 below.
Another source of error in the estimates is sampling variance. Sampling variance is a measure of the fluctuation between estimates from different samples using the same sample design. Sampling variance in the NCS is calculated using a technique called balanced half-sample replication. For national estimates this is done by forming 128 different re-groupings of half of the sample units. For each half-sample, a "replicate" estimate is computed with the same formula as the regular or "full-sample" estimate, except that the final weights are adjusted. If a unit is in the half-sample, its weight is multiplied by (2-k); if not, its weight is multiplied by k. For all NCS publications, k = 0.5, so the multipliers are 1.5 and 0.5. Sampling variance computed using this approach is the sum of the squared difference between each replicate estimate and the full sample estimate averaged over the number of replicates and adjusted by the factor of 1/(1-k)2 to account for the adjustment to the final weights. For more details, see the NCS Chapter of the BLS Handbook of Methods. Standard error, which is the square root of variance, for primary aggregate estimates of the index of quarterly change is typically less than 0.5 percent. Relative standard error, which is the square root of variance divided by the estimate, for aggregate estimates of compensation, wage, or benefit levels are typically less than 5 percent. The standard errors or relative standard errors are included within published NCS reports at the following website: http://www.bls.gov/ncs/ect/ectvar.htm.
Variance estimation also serves another purpose. It identifies industries and occupations that contribute substantial portions of the sampling variance. Allocating more sample units to these domains often improves the efficiency of the sample. These variances will be considered in allocation and selection of the future replacement samples.
2d. Data Collection Cycles
NCS data are collected quarterly for all schedules.
3. Non-Response
There are three types of non-response: permanent non-response, temporary non-response, and partial non-response. The non-responses can occur at the establishment level, occupation level, or benefit item level. The assumption for all non-response adjustments is that non-respondents are similar to respondents.
To adjust for permanent establishment or occupation non-response at the initial interview, weights of responding units or occupations that are deemed to be similar are adjusted appropriately. Establishments are considered similar if they are in the same ownership and 2-digit NAICS. If there are no sufficient data at this level, then a broader level of aggregation is considered.
For temporary and partial non-response, a replacement value is imputed based on information provided by establishments with similar characteristics. Imputation is done separately for each benefit both in the initial period and in subsequent update periods. Imputation is also done for each missing wage estimate after the initial period. In the rare event that the BLS cannot determine whether or not a benefit practice exists for a non-respondent, the average cost is imputed based on data from all responding establishments (including those with no plans and plans with zero costs).
There is a continuous effort to maximize response rates. We are developing and providing respondents with new and useful products. Examples include the Beyond the Numbers publications (http://www.bls.gov/opub/btn/) and industry briefs on selected industries that are provided to field economists to help them identify industry-specific collection challenges. We are continually exploring alternative methods for respondents to report their data.
As previously stated in Part A, for September 2014, the unweighted response rates for the NCS were 78% at initiation and 91% at update. Additionally, the response rate based on weighted employment is expected to be about 74 percent for initiation schedules and 93% for update schedules that responded at initiation.
3a. Maximize Response Rates
To maximize the response rate for this survey, field economists initially refine addresses ensuring appropriate contact with the employer. Then, employers are mailed a letter explaining the importance of the survey and the need for voluntary cooperation. The letter also includes the Bureau’s pledge of confidentiality. A field economist calls the establishment after the package is sent and attempts to enroll them into the survey. Non-respondents and establishments that are reluctant to participate are re-contacted by a field economist specially trained in refusal aversion and conversion. Additionally, respondents are offered a variety of methods, including telephone, fax, email, and the internet, through which they can provide data.
3b. Non-Response Adjustment
As with other surveys, NCS experiences a certain level of non-response. To adjust for the non-responses, NCS has divided the non-response into two groups, 1) unit non-respondents and 2) item non-respondents. Unit non-respondents are the establishments that do not report any compensation data, whereas item non-respondents are the establishments that report only a portion of the requested compensation data, such as wages for a sub-set of sampled jobs.
The unit non-response is treated using a Non Response Adjustment Factor (NRAF) as explained in the estimation procedure section of this document. Item non-response is adjusted using item imputation. Within each sampling cell, NRAFs are calculated each year based on the ratio of the number of viable establishments to the number of usable respondents in that month. The details regarding the NRAF procedure are given in Chapter 8 of the Bureau of Labor Statistics’ Handbook of Methods (http://www.bls.gov/opub/hom/pdf/homch8.pdf).
The method used to adjust for item non-response at the establishment and quote level is a cell-mean-weighted procedure. Details of this procedure are available in BLS Handbook of Methods (http://www.bls.gov/opub/hom/pdf/homch8.pdf). Other techniques are used to impute for item non-response for benefit estimates and are described in the following CWC article: “Recent Modifications of Imputation Methods for National Compensation Survey Benefits Data”, may be found at the following link: http://www.bls.gov/opub/mlr/cwc/recent-modification-of-imputation-methods-for-national-compensation-survey-benefits-data.pdf.
3c. Non-Response Bias Research
Extensive research was done to assess whether the non-respondents to the NCS survey differ systematically in some important respect from the respondents of the survey and would thus bias NCS estimates. Details of this study are described in the two papers by Ponikowski, McNulty, and Crockett referenced in Section 6 (see references below).
Additional work has begun to evaluate potential bias in benefits data using IRS Form 5500 data. In FY2013, NCS coordinated a study, in conjunction with the Employee Benefits Security Administration (EBSA) and carried out by Deloitte, to determine the potential for productive use of linkages between the NCS and data collected from IRS Form 5500s. The project established that extensive linkage is possible between the two data sources, and followed up with some preliminary exploration of how these linkages could be best exploited. In FY2015, NCS is conducting a second round of this work. A principal goal of this round of research is to develop useful applications of the linkages established in the first round, especially as regards Defined Benefit plans. One of the most promising applications to be explored is the potential for using the linked data to measure response biases which might affect NCS benefits publications. What can be learned from the extensive, but imperfect, linkage between establishments in the NCS sampling frame that do not provide complete responses about their benefit offerings and the universe of Defined Benefit plans contained in the 5500 data base? What are the implications, if any, for the methods NCS uses to adjust for non-response in producing its outputs?
4. Testing Procedures
4a. Tests of Collection Procedures
NCS is in the initial stages of identifying other potential changes to the data that is collected from respondents, each of which will be tested by the BLS Cognitive Laboratory before full implementation. Some potential changes that could be tested are related to changes in employer provided health care with the implementation of the Affordable Care Act (ACA). NCS is currently gathering more information about the potential impact of this legislation on the data collected and provided. Once we better understand the potential impact on our estimates and collected data, NCS will work closely with the Cognitive Laboratory to identify and test the changes to the data collected.
The NCS program chartered several teams to research and determine what aspects of the Affordable Care Act could impact NCS output. The ACA could impact data on the cost, coverage, and provisions of employment-based health care benefits. Since the biggest unknown was what new or different information would come from employers, a feasibility test was needed before any changes were implemented.
The purpose of the NCS Affordable Care Act Feasibility test was to gauge how well NCS can capture important information as it pertains to the act’s provisions. In the summer of 2014, the test was conducted on NCS private industry establishments and sought the impact the ACA had on employee health insurance plans as well as determining changes employers had made and planned to make to health insurance offerings because of the ACA.
The ACA feasibility test investigated a number of new terms, concepts, and features. The employers were asked what they knew about various features of the act, including essential benefits, grandfathered plans, variable premiums, tax credits, and metal ratings for actuarial values. The level of knowledge varied. What we learned is that there is a lot of uncertainty. Some employers indicated they plan to make changes in their health benefit coverage, while others believed that no changes would be necessary. Many others planned to wait and see. Before implementing many changes to our data collection and estimation efforts, NCS will need to conduct further testing, to cover such topics as employer penalties, Cadillac plans, and more.
One area where respondents were able to provide data during the test was related to “Grandfathered plans.” Grandfathered plans are those that were in existence on March 23, 2010 and haven’t been changed in ways that substantially cut benefits or increase costs for consumers. Grandfathered plans could enroll people after March 23, 2010 and still maintain their grandfathered status. There is some question about which health plans under the Affordable Care Act are Grandfathered Plans. NCS plans to begin collecting whether or not each health insurance plan is a Grandfathered plan during the collection of the March 2015 and June 2015 quarters from all active establishments in the NCS sample to capture and provide estimates on Grandfathered Plans. The Grandfathered Plan question will be added to the Integrated Data Capture (IDC) system for data entry.
4b. Tests of Survey Design Procedures
The final approved budget for FY 2011 called for an alternative to the LPS component of the NCS, a new approach that uses data from two current BLS programs – the Occupational Employment Statistics (OES) survey and ECI. This may allow for the production of additional locality pay data, while still meeting the requirement to provide data to the President’s Pay Agent and to produce the other NCS estimates. With this change, the NCS has been redesigned. The changes are: a non-area-based national design instead of an area-based survey design; a reduction in sample size of approximately 25%; and a move from a 5-year rotation cycle to a 3-year rotation cycle. At the same time, NCS has implemented a model-based estimation approach to produce data for the President’s Pay Agent. NCS implemented a model-based estimation approach that allows BLS to continue to produce wage estimates by worker characteristic such as full-time vs. part-time or union vs. non-union. NCS completed the evaluation and testing for this change in three separate sets of activities.
First, the BLS staff examined potential changes to the NCS sample design that included the following options:
Moving from an area-based sample design to a national design, thus eliminating the first stage of sampling to select areas
Implementing a new allocation methodology to correspond with the non-area-based sampling
Moving from a five-year rotation to a three-year rotation for private industry establishments
For each of these options, NCS tested the proposed change using the general scheme described below.
Obtain a full frame of data,
Use establishment total wage data from the frame to compute average monthly wages across all establishments,
Implement the proposed change using the full frame of data,
Select multiple (100 or more) simulated samples using the proposed methodology,
Compute estimates of the average monthly wages using the weighted data from each of the simulated samples,
Compute the mean and standard error of the average monthly wages across all the simulated samples, and
Compare the estimated average monthly wages across the simulated samples to those from the frame.
In addition to analyzing the potential effect of the redesign on the reliability of the estimates, we also studied the effect of any redesign on response rates and bias as described in the attached paper, "Update on the Evaluation of Sample Design Issues in the National Compensation Survey", by Ferguson et al.
The NCS also evaluated options for the transition to a national design for State and local government samples. This research and evaluation were done using similar methods to those used for the private industry sample design evaluation. This research is documented in the paper “State and Local Government Sample Design for the National Compensation Survey” by Ferguson et al.
The sample design for State and local government was tested using sample simulations for which we obtained a complete sample frame from the second quarter of 2011, assigned measures of size, executed the allocation process, and selected certainty establishments. We then selected 100 non-certainty samples and evaluated the resulting samples to ensure that the total weighted employment for the samples matched the frame employment and that the desired sample sizes were obtained.
Based on prior experience and a preliminary analysis of the proposed design changes, we believe that the ECI, ECEC, and incidence and key provisions benefits products from the NCS will be of about the same quality as the current estimates. We also believe that we will be able to continue publishing most, if not all, of the current detailed estimates for these product lines. Estimates in the NCS detailed benefits product line are produced from the current initiation sample only. Due to a move to a three-year rotation, each initiation sample will be larger than the current five-year rotation sample even though NCS will implement a sample reduction. The larger sample that will be used to produce the detailed benefits provisions products will hopefully result in some increased accuracy for these estimates.
Testing of Modeled Wage Estimates
NCS continues to evaluate and test the potential of producing estimates of worker wages by worker characteristics using data from both the NCS and the Occupational Employment Survey (OES). This data would be produced using a wage model that uses the large quantity of wage data available from OES along with the detailed worker characteristics from the NCS. The model is described in the August 2013 Monthly Labor Review article titled “Wage estimates by job characteristic: NCS and OES program data” by Lettau and Zamora.
In FY 2014, three related projects on the publishability of NCS-OES Wage Estimates by Job Characteristic were undertaken. The aim of Project 1 is to evaluate the reliability of producing estimates for large numbers of geographic areas, particularly those for which the NCS data alone are not sufficient to produce direct (unmodeled) estimates. Project 2 seeks to assess the aspect of the methodology that requires three NCS quotes in a wage interval-six digit SOC-area cell to allocate employment by characteristics. Finally, Project 3 attempts to answer the question of how many NCS quotes are required to be present in an area-six-digit SOC-characteristic cell to make an estimate publishable.
While Project 2 has not yet been completed, results from Project 1 and Project 3 are now available. Before summarizing them, a caveat is in order: owing to the small size of the NCS sample, it was not possible to examine estimates for a large portion of employment that the NCS-OES estimates cover. For Project 1, the findings provide support for the notion that NCS-OES estimates can be reliable for geographic areas for which it would not be possible to compute direct NCS-only estimates. The main finding of Project 3 is that estimates supported by only 1-2 NCS quotes do not have a high degree of reliability. While reliability tends to increase with the number of quotes, the results here do not offer clear guidelines on where to impose a cutoff.
Also in FY 2014, research was undertaken by Westat to develop an automated approach for validating the large quantity of wage modeled estimates. Westat developed a regression model that calculates an expected mean wage of an occupation by job characteristic, which could be used for validation purposes to compare with the job characteristic estimate produced from the wage model. When implemented, the wage model system could generate several reports to assist reviewers with the validation of wage model estimates. These include reports that compare current year estimates to prior year estimates; that compare the characteristic relationship (i.e., union compared to nonunion) of the modeled estimates to the characteristic relationship of estimates calculated from only NCS data; and that list the estimates that barely passed the residual threshold. During FY 2015, NCS will be developing plans for implementing and disseminating the wage model estimates.
Development and Testing of a New Data Capture System
The NCS is in the early stages of planning, coordinating, developing, and implementing a new data capture application. The Compensation Information Entry and Review Application (CIERA) will replace the Integrated Data Capture (IDC) system as the primary data capture tool for all of the NCS products. Due to the vast amount of data collected across the various NCS product lines, this project is expected to span multiple years and will be released as major sections are completed. The team working on this project is gathering data from staff both in the Regional Offices as well as the National Office to create what are called “User Stories” or requirements to accommodate the various needs of this system. The team is using the AGILE Scrum software development methodology for planning, development and implementation. Agile software development is a technique in which requirements and solutions are developed through on-going collaboration between and across functional teams. This method of software development promotes adaptive planning, evolutionary development, timely delivery, continuous improvement and encourages rapid and flexible response to change.
5. Statistical and Analytical Responsibility
Ms. Gwyn Ferguson, Chief, Statistical Methods Group of the Office of Compensation and Working Conditions, is responsible for the statistical aspects of the NCS program. Ms. Ferguson can be reached on 202-691-6941. BLS seeks consultation with other outside experts on an as needed basis.
6. References
Attachment 1 - Ferguson, Gwyn, Coleman, Joan L., Ponikowski, Chester, (August 2011), “Update on the Evaluation of Sample Design Issues in the National Compensation Survey,” ASA Papers and Proceedings, http://www.bls.gov/osmr/abstract/st/st110230.htm
Attachment 2 - Ferguson, Gwyn R., Ponikowski, Chester H., McNulty, Erin, and Coleman, Joan L., (September 2012), “State and Local Government Sample Design for the National Compensation Survey”, ASA Papers and Proceedings, http://www.bls.gov/osmr/pdf/st020150.pdf
Additional References:
Crockett, Jackson, McNulty, Erin, Ponikowski, Chester H., (October 2008), “Update on Use of Administrative Data to Explore Effect of Establishment Non-response Adjustment on the National Compensation Survey Estimates,” ASA Papers and Proceedings, http://www.bls.gov/osmr/pdf/st080190.pdf
Cochran, William, G., (1977), Sampling Techniques 3rd Ed., New York, Wiley and Sons, 98, 259-261.
Ernst, Lawrence R., Guciardo, Christopher J., Ponikowski, Chester H., and Tehonica, Jason, (August 2002), “Sample Allocation and Selection for the National Compensation Survey,” ASA Papers and Proceedings, http://www.bls.gov/osmr/pdf/st020150.pdf
Federal Committee on Statistical Methodology, Subcommittee on Disclosure Limitation Methodology, "Statistical Policy Working Paper 22," http://www.fcsm.gov/working-papers/SPWP22_rev.pdf
Ferguson, Gwyn, Ponikowski, Chester, Coleman, Joan, (August 2010), “Evaluating Sample Design Issues in the National Compensation Survey,” ASA Papers and Proceedings, www.bls.gov/osmr/abstract/st/st100220.htm |
Izsak, Yoel, Ernst, Lawrence R., McNulty, Erin, Paben, Stephen P., Ponikowski, Chester H., Springer, Glenn, and Tehonica, Jason, (August 2005), “Update on the Redesign of the National Compensation Survey,” ASA Papers and Proceedings, http://www.bls.gov/osmr/pdf/st050140.pdf
Lettau, Michael K. and Zamora, Dee A., Monthly Labor Review (August 2013), “Wage estimates by job characteristic: NCS and OES program data”, http://www.bls.gov/opub/mlr/2013/article/lettau-zamora-1.htm
Ponikowski, Chester H., and McNulty, Erin E., (December 2006), “Use of Administrative Data to Explore Effect of Establishment Nonresponse Adjustment on the National Compensation Survey Estimates,” ASA Papers and Proceedings, http://www.bls.gov/osmr/pdf/st060050.pdf
Schumann, Richard E., "Occupational Selection and Leveling in the National Compensation Survey", U.S. Bureau of Labor Statistics, Compensation and Working Conditions Online,
Originally Posted on August 31, 2011, http://www.bls.gov/opub/cwc/cm20110829ar01p1.htm
Stafira, Sarah, (August 2009), “Recent Modification of Imputation Methods for National Compensation Survey Benefits Data, U.S. Bureau of Labor Statistics, Compensation and Working Conditions Online, http://www.bls.gov/opub/mlr/cwc/recent-modification-of-imputation-methods-for-national-compensation-survey-benefits-data.pdf
US Bureau of Labor Statistics, “BLS Handbook of Methods: Chapter 8 National Compensation Methods,” http://www.bls.gov/opub/hom/pdf/homch8.pdf
|
1 Ponikowski, Chester H. and McNulty, Erin E., " Use of Administrative Data to Explore Effect of Establishment Nonresponse Adjustment on the National Compensation Survey", 2006 Proceedings of the American Statistical Association, Section on Survey Methods Research [CD-ROM], American Statistical Association, 2006
http://www.bls.gov/ore/abstract/st/st060050.htm
| File Type | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
| Author | GRDEN_P |
| File Modified | 0000-00-00 |
| File Created | 2021-01-26 |
© 2026 OMB.report | Privacy Policy