FACES 2014_2018 Data Collection OMB Part B_05 07 14
FACES 2014_2018 Data Collection OMB Part B_05 07 14.docx
Head Start Family and Child Experiences Survey (FACES 2014-2018)
OMB: 0970-0151
Head Start Family and Child Experiences Survey (FACES 2014–2018) OMB Supporting Statement for Data Collection
Part B: Collection of Information Involving Statistical Methods
CONTENTS
B. STATISTICAL METHODS (USED FOR COLLECTION OF INFORMATION EMPLOYING STATISTICAL METHODS) 1
B.1. Respondent Universe and Sampling Methods 1
B.2. Procedures for Collecting Information 4
1. Sampling and Estimation Procedures 4
2. Data Collection Procedures 8
B.3. Methods to Maximize Response Rates and Data Reliability 11
B.4. Test of Procedures or Methods 12
B.5. Individuals Consulted on Statistical Methods 12
APPENDICES
APPENDIX C: STUDY INTRODUCTION MATERIALS
APPENDIX H: ADVANCE MATERIALS
TABLES
B.1 FACES 2014–2018 Minimum Detectable Differences 7
FIGURES
B.1 Flow of Sample Selection Procedures 3
ATTACHMENTS
ATTACHMENT 1: Classroom sampling form from Head Start staff
ATTACHMENT 2: Child roster form from Head Start staff
ATTACHMENT 3: HEAD START CORE CHILD ASSESSMENT
ATTACHMENT 4: HEAD START CORE PARENT SURVEY
ATTACHMENT 5: HEAD START FALL SUPPLEMENTAL PARENT SURVEY
ATTACHMENT 6: HEAD START CORE TEACHER CHILD REPORT
B. STATISTICAL METHODS (USED FOR COLLECTION OF INFORMATION EMPLOYING STATISTICAL METHODS)
The Office of Planning, Research and Evaluation (OPRE), Administration for Children and Families (ACF), U.S. Department of Health and Human Services (HHS), is proposing to collect data for a new round of the Head Start Family and Child Experiences Survey (FACES). FACES 2014–2018 features a new Core Plus study design that consists of two Core studies—the Classroom + Child Outcomes Core and the Classroom Core—and Plus studies, which will include additional survey content of policy or programmatic interest. The Classroom + Child Outcomes Core, occurring during the 2014–2015 program year, collects child-level data, along with program and classroom data, from a subset of programs, while other programs will only have data collected on program and classroom information (see Part A for details). In spring 2017, we will conduct the Classroom Core focusing on program and classroom data collection for all programs.
The current information collection request includes data collection activities for FACES 2014–2018, including the collection of information that is used to select classrooms and children for the study, conducting child assessments and parent surveys, and obtaining Head Start teacher reports on children’s development. A previous request approved the FACES 2014–2018 sampling plans for Head Start programs, centers, classrooms, and children, as well as the procedures for recruiting programs and selecting centers in 2014 and contacting them again in 2016.
B.1. Respondent Universe and Sampling Methods
The target population for FACES 2014–2018 is all Head Start programs in the United States, their classrooms, and the children and families they serve. The sample design is similar to the one used for FACES 2009 in some respects, but with some key differences noted below. FACES 2014–2018 will use a stratified multistage sample design with four stages of sample selection: (1) Head Start programs, with programs defined as grantees or delegate agencies providing direct services; (2) centers within programs; (3) classes within centers; and (4) for a random subsample of programs, children within classes. To minimize the burden on parents/guardians who have more than one child selected for the sample, we will also randomly subsample one selected child per parent/guardian, a step that was introduced in FACES 2009.
The frame that will be used to sample programs is the 2012–2013 Head Start Program Information Report (PIR), which is an updated version of the frame used for previous rounds of FACES. We will exclude from the sampling frame: Early Head Start programs, programs in Puerto Rico and other U.S. territories, migrant and seasonal worker programs, programs that do not directly provide services to children in the target age group, programs under transitional management, and programs that are (or will soon be) defunded.1 We will develop the sampling frame for centers through contacts with the sampled programs. Similarly, the study team will construct the classroom and child frames after centers and classroom samples are drawn. All centers, classrooms, and children in study-eligible, sampled programs will be included in the center, classroom, and child frames, respectively, with two exceptions. Classrooms that receive no Head Start funding (such as prekindergarten classrooms in a public school setting that also has Head Start-funded classrooms) are ineligible. Also, sampled children who leave Head Start between fall and spring of the program year become ineligible for the study. Sampling of centers, classrooms, and children, which we describe below, is not a part of information-gathering activities for which clearance is being requested in this submission.
The sample design for the new round of FACES is based on the one used for FACES 2009, which was based on the designs of the four previous rounds. But unlike the earlier rounds of FACES, the sample design for FACES 2014–2018 will involve sampling for two newly designed study components: the Classroom + Child Outcomes Core and the Classroom Core. The Classroom + Child Outcomes Core study will involve sampling at all four stages (programs, centers, classrooms, and children), and the Classroom Core study will involve sampling at the first three stages only (excluding sampling of children within classes). Under this design, the collective sample size across the two studies will be larger than in prior rounds of FACES at the program, center, and classroom levels, allowing for more powerful analyses of program quality, especially at the classroom level. Also new to the FACES 2014–2018 design, the child-level sample will represent children enrolled in Head Start for the first time and those who are attending a second year of Head Start. This will allow for a direct comparison of first- and second-year program participants and analysis of child gains during the second year. Previously, FACES followed newly enrolled children through one or two years of Head Start and then through spring of kindergarten. FACES 2014–2018 will follow the children only through the fall and spring of one program year.
To minimize the effects of unequal weighting on the variance of estimates, we propose sampling with probability proportional to size (PPS) in the first two stages. At the third stage, we will select an equal probability of classrooms within each sampled center and, in centers where children are to be sampled, an equal probability sample of children within each sampled classroom. The measure of size for PPS sampling in each of the first two stages will be the number of classrooms. This sampling approach maximizes the precision of classroom-level estimates and allows for easier in-field sampling of classrooms and children within classrooms. We will select a total of 180 programs across both Core study components. Sixty of the 180 programs sampled for the Core study will be randomly subsampled with equal probability within strata to be included in the Classroom + Child Outcomes study. Within these 60 programs, we will select, if possible, two centers per program, two classes per center, and a sufficient number of children to yield 10 consented children per class, for a total of about 2,400 children at baseline.
Based on our experience with earlier rounds of FACES, we estimate that 70 percent of the 2,400 baseline children (about 1,680) will be new to Head Start. We expect a program and study retention rate of 90 percent from fall to spring, for a sample of 2,160 study children in both fall 2014 and spring 2015, of which about 1,512 (70 percent) are estimated to have completed their first Head Start year.
The Classroom Core study component will include the 60 programs where students are sampled plus the remaining 120 programs from the sample of 180. From the additional 120 programs, we will select two centers per program and two classrooms per center. Across both study components, we will collect data from a total of 360 centers and 720 classrooms in spring 2015. For follow-up data collection in spring 2017, we will select a refresher sample2 of programs and their centers so that the new sample will be representative of all programs and centers at the time of follow-up data collection, and we will select a new sample of classrooms in all centers. Figure B.1 is a diagram of the sample selection and data collection procedures. At each sampling stage, we will use a sequential sampling technique based on a procedure developed by Chromy.3
Figure B.1. Flow of Sample Selection Procedures
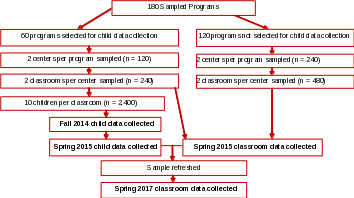
For the Core studies, we will initially select 360 programs, and pair adjacent selected programs within strata. (These paired programs would be similar to one another with respect to the implicit stratification variables.) We will then randomly select one from each pair to be released as part of the main sample of programs. After the initial 180 programs are selected, we will ask the Office of Head Start (OHS) to confirm that the 180 selected programs are in good standing. If confirmed, we will contact each program and recruit them to participate in the study: the 60 programs subsampled for the Classroom + Child Outcomes Core will be recruited in spring 2014 (for fall 2014 participation), and the remaining 120 programs will be recruited in fall 2014 (for spring 2015 participation). If the program is not in good standing or refuses to participate, we will release the other member of the program’s pair into the sample and go through the same process of confirmation and recruitment with that program. We will count all released programs as part of the sample for purposes of calculating response rates and weighting adjustments. At subsequent stages of sampling, we will release all sampled cases, expecting full participation among the selected centers and classes. At the child level, we estimate that out of 12 selected children per class, we will end up with 10 eligible children with parental consent, which is our target. We expect to lose, on average, two children per class, either because they are no longer enrolled, because parental consent was not granted, or because siblings were subsampled.
We will select centers PPS within each sampled program using the number of classrooms as the measure of size, again using the Chromy procedure. For the Classroom + Child Outcomes Core, we will randomly select classrooms within centers with equal probability. Classrooms with very few children will be grouped with other classrooms in the same center for sampling purposes to ensure a sufficient sample yield.4 Once classrooms are selected, we will select an equal probability sample of 12 children per class, with the expectation that 10 will be eligible and will receive parental consent.
B.2. Procedures for Collecting Information
1. Sampling and Estimation Procedures
Statistical methodology for stratification and sample selection. The sampling methodology is described under item B1 above. When sampling programs, we will form explicit strata using census region, metro/nonmetro status, and percentage of racial/ethnic minority enrollment. Sample allocation will be proportional to the estimated fraction of eligible classrooms represented by the programs in each stratum.5 We will implicitly stratify (sort) the sample frame by other characteristics, such as percentage of dual language learner (DLL) children (categorized), whether the program is a public school district grantee, and the percentage of children with disabilities. No explicit stratification will be used for selecting centers within programs, classes within centers, or children within classes, although some implicit stratification (such as the percentage of children who are dual language learners) may be used for center selection.
Estimation procedure. We will create analysis weights to account for variations in the probabilities of selection and variations in the eligibility and cooperation rates among those selected. For each stage of sampling (program, center, class, and child) and within each explicit sampling stratum, we will calculate the probability of selection. The inverse of the probability of selection within stratum at each stage is the sampling or base weight. The sampling weight takes into account the PPS sampling approach, the presence of any certainty selections, and the actual number of cases released. We treat the eligibility status of each sampled unit as known at each stage. Then, at each stage, we will multiply the sampling weight by the inverse of the weighted response rate within weighting cells (defined by sampling stratum) to obtain the analysis weight, so that the respondents’ analysis weights account for both the respondents and nonrespondents.
Thus, the program-level weight adjusts for the probability of selection of the program and response at the program level; the center-level weight adjusts for the probability of center selection and center-level response; and the class-level weight adjusts for the probability of selection of the class and class-level response. The child-level weights adjust for the subsampling probability of programs for the Classroom + Child Outcomes Core; the probability of selection of the child within classroom, whether parental consent was obtained, and whether various child-level instruments (for example, direct child assessments and parent surveys) were obtained. The formulas below represent the various weighting steps for the cumulative weights through prior stages of selection, where P represents the probability of selection and RR the response rate at that stage of selection. Because FACES 2014–2018 includes all children (not just those newly enrolled), we will post-stratify to know totals at each weighting stage.
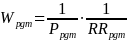
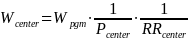
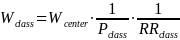
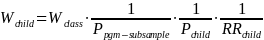
Degree of accuracy needed for the purpose described in the justification. The complex sampling plan, which includes several stages, stratification, clustering, and unequal probabilities of selection, requires using specialized procedures to calculate the variance of estimates. Standard statistical software assumes independent and identically distributed samples, which would indeed be the case with a simple random sample. A complex sample, however, generally has larger variances than would be calculated with standard software. Two approaches for estimating variances under complex sampling, Taylor Series and replication methods, can be estimated by using SUDAAN and special procedures in SAS, Stata, and other packages.
Most of the analyses will be at the child and classroom levels. Given various assumptions about the sample design and its impact of estimates, the sample size should be sufficiently large to detect meaningful differences. In Table B.1, we show the minimum detectable differences with 80 percent power (and = 0.05) and various sample and subgroup sizes, assuming different intraclass correlation coefficients for classroom- and child-level estimates at the various stages of clustering (see table footnote).
For point-in-time estimates, we are making the conservative assumption that there is no covariance between estimates for two subgroups, even though the observations may be in the same classes, centers, and/or programs. By conservative, we mean that smaller differences than those shown will likely be detectable. For pre-post estimates, we do assume covariance between the estimates at two points in time. Evidence from another survey shows expected correlations between fall and spring estimates of about 0.5. Using this information, we applied another design effect component to the variance of estimates of pre-post differences to reflect the fact that it is efficient to have many of the same children or classes at both time points.
The top section of Table B.1 (labeled “Point in Time Subgroup Comparisons”) shows the minimum differences that would be detectable for point-in-time (cross-sectional) estimates at the class and child levels. We have incorporated the design effect attributable to clustering. The bottom section (labeled “Estimates of Program Year Gains”) shows detectable pre-post difference estimates at the child level. Examples are given below.
The columns farthest to the left (“Subgroups” and “Time Points”) show several sample subgroup proportions (for example, a comparison of male children to female children would be represented by “50, 50”). The child-level estimates represent two scenarios: (1) all consented children in fall 2014 (n = 2,400) and (2) all children in spring 2015 who remained in Head Start (n = 2,160). For example, the n = 2,400 row within the “33, 67” section represents a subgroup comparison involving children at the beginning of data collection for two subgroups, one representing one-third of that sample (for example, children in bilingual homes), the other representing the remaining two-thirds (for example, children from English-only homes).
The last few columns (“MDD”) show various types of variables from which an estimate might be made; the first two are estimates in the form of proportions, the next is an estimate for a normalized variable (such as an assessment score) with a mean of 100 and standard deviation of 15 (for child-level estimates only), and the last shows the minimum detectable effect size—the MDD in standard deviation-sized units. The numbers for a given row and column show the minimum underlying differences between the two subgroups that would be detectable for a given type of variable with the given sample size and design assumptions.
If we were to compare two equal-sized subgroups of the 720 classrooms in spring 2015, our design would allow us to detect a minimum difference of .280 standard deviations with 80 percent power. At the child level, if we were to compare normalized assessment scores with a sample size of 2,400 children in fall 2014, and two approximately equal-sized subgroups (such as boys and girls), our design would allow us to detect a minimum difference of 3.578 points with 80 percent power. If we were to compare these two subgroups again in the spring of 2015, our design would allow us to detect a minimum difference of 3.617 points.
If we were to perform a pre-post comparison (fall 2014 to spring 2015) for the same normalized assessment measure, we would be able to detect a minimum difference of 1.887 points. If we were to perform the same pre-post comparison for a subgroup representing 40 percent of the entire sample (n = 960 in fall 2014; n = 864 in spring 2015), we would be able to detect a minimum difference of 2.98 points.
Unusual problems requiring specialized sampling procedures. We do not anticipate any unusual problems that require specialized sampling procedures.
Any use of periodic (less frequent than annual) data collection cycles to reduce burden. We do not plan to reduce burden by collecting data less frequently than once per year.
Table B.1. FACES 2014–2018 Minimum Detectable Differences
POINT IN TIME SUBGROUP COMPARISONS |
|
||||||||
Time Point |
Subgroups |
Minimum Detectable Difference |
|
||||||
Percentage in Group 1 |
Percentage in Group 2 |
Classes
in |
Classes
in |
Proportion
of |
Proportion
of |
|
Minimum Detectable Effect Size |
||
Spring 2015 |
50 |
50 |
360 |
360 |
.084 |
.140 |
|
.280 |
|
33 |
67 |
238 |
482 |
.090 |
.149 |
|
.298 |
||
15 |
85 |
108 |
612 |
.119 |
.198 |
|
.392 |
||
Time Point |
Percentage in Group 1 |
Percentage in Group 2 |
Children in Group 1 |
Children in Group 2 |
Proportion
of |
Proportion
of |
Normalized Variable (Mean = 100, s.d.= 15) |
Minimum Detectable Effect Size |
|
Fall 2014 |
50 |
50 |
1,200 |
1,200 |
.072 |
.119 |
3.578 |
.239 |
|
33 |
67 |
792 |
1,608 |
.076 |
.127 |
3.805 |
.254 |
||
40 |
30 |
960 |
720 |
.087 |
.144 |
4.321 |
.288 |
||
Spring 2015 |
50 |
50 |
1,080 |
1,080 |
.072 |
.121 |
3.617 |
.241 |
|
ESTIMATES OF PROGRAM YEAR GAINS |
|
||||||||
Time Points |
Minimum Detectable Difference |
|
|||||||
Time 1 |
Time 2 |
Percent Subgroup at Both Times |
Children
at |
Children
at |
Proportion
of |
Proportion
of |
Normalized Variable (Mean = 100, s.d.= 15) |
Minimum Detectable Effect Size |
|
Fall 2014 |
Spring 2015 |
100 |
2,400 |
2,160 |
.038 |
.063 |
1.887 |
.126 |
|
70 |
1,680 |
1,512 |
.045 |
.075 |
2.255 |
.150 |
|||
40 |
960 |
864 |
.060 |
.100 |
2.983 |
.199 |
|||
Note: Conservative assumption of no covariance for point-in-time subgroup comparisons. Covariance adjustment made for pre-post difference (Kish, p. 462, Table 12.4.II, Difference with Partial Overlap). Assumes =.05 (two-sided), .80 power. For classroom-level estimates, assumes 180 programs, 360 centers, between-program ICC = .2, between-center ICC = .2. For child-level estimates, assumes 60 programs, 120 centers, between-program ICC = .05, between-center ICC = .05, between-classroom ICC = .05.
s.d. = standard deviation
The minimum detectable effect size is the minimum detectable difference in standard-deviation-sized units.
2. Data Collection Procedures
As in previous rounds of FACES, we propose to collect data from several sources: Head Start children, their parents, and Head Start staff (program directors, center directors, and teachers). Although FACES 2014–2018 follows a new Core Plus study design, many data collection features are the same or build on procedures that proved successful for FACES 2009 while adding enhancements to increase efficiency and lower costs. Table A.1 (in Part A) shows the instrument components, sample size, type of administration, and periodicity.
The period of field data collection for the Classroom + Child Outcomes Core is ten weeks long, beginning in September for the fall 2014 wave and in March for the spring 2015 wave. A member of the study team (led by Mathematica Policy Research), in conjunction with the Head Start program’s on-site coordinator (a designated Head Start program staff member who will work with the study team to recruit teachers and families and help schedule site visits), will schedule the data collection week based on the program’s availability. The study team will schedule a maximum of ten sites for visits each week. Approximately two weeks before the program’s data collection visit, the study team will send parents email invitations for the parent survey. For consents received during the data collection visit, the study team will send out parent emails on a rolling basis.6
Below we outline the procedures for each of the Core data collection instruments (and anticipated marginal response rates). The instruments that will be used in FACES 2014–2018 are streamlined versions of those used in FACES 2009. The current information collection request covers instruments one through six below. The study team will administer these instruments in fall 2014 and, except for instrument two, again in spring 2015. Instruments seven through thirteen will be administered in spring 2015 or subsequent rounds and will be submitted for review through a future request. These instruments will either support the Core study at the program or classroom levels or be used for future Plus studies. Any Plus activities using Core instruments will follow the same procedures as the Core data collection. Potential data collection activities for Plus studies might differ from the Core activities, depending on the nature of the study.7
Head Start classroom sampling form (Attachment 1). Upon arrival at a selected center, a Field Enrollment Specialist (FES) will request a list of all Head Start-funded classrooms from Head Start staff (typically the On-Site Coordinator). Head Start staff may provide this information in various formats such as print outs from an administrative record system or photocopies of hard copy list or records. The FES will enter the information into a tablet computer. For each classroom, the FES will enter the teacher’s first and last names, the session type (morning, afternoon, full day, or home visitor), and the number of Head Start children enrolled into a web-based sampling program via the tablet computer. The sampling program will select about two classrooms for participation in the study. In FACES 2009, no On-Site Coordinators refused to provide this information.
Head Start child roster form (Attachment 2). For each selected classroom, the FES will request the names and dates of birth of each child enrolled in the selected classroom from Head Start staff (typically the On-Site Coordinator). Head Start staff may provide this information in various formats such as print outs from an administrative record system or photocopies of hard copy list or records. The FES will use a tablet computer to enter this information into a web-based sampling program. The program will select up to 12 children for participation in the study. For these selected children only, the FES will then enter each child’s gender, home language, and parent’s name into the sampling program. Finally, the FES will ask Head Start staff (typically the On-Site Coordinator) to identify among the 24 selected children any siblings. The FES will identify the sibling groups in the sampling program and the sampling program will then drop all but one member of each sibling group, leaving one child per family.
Head Start core child assessments (Attachment 3). The study team will conduct direct child assessments in fall 2014 and spring 2015 during the scheduled data collection week. The on-site coordinator will schedule child assessments at the Head Start center. Parents will be reminded of the child assessments the week before the field visit via reminder notices sent home with their child (Appendix H-1). On average, child assessments take approximately 45 minutes. A trained assessor will use computer-assisted personal interviewing with a tablet computer to conduct the child assessments one-on-one, asking questions and recording the child’s responses. We anticipate completing assessments for at least 92 percent of the sampled children in fall and at least 83 percent of those children in spring.
Head Start core parent surveys (Attachment 4). On average, each parent survey is approximately 20 minutes long. With the introduction of web-based surveys with a low-income population, we plan to conduct an experiment to understand how response rates and costs are affected by this new option. In particular, we are interested in whether it is cost-effective to use a web survey as compared to a telephone-administered survey with a low-income population and whether parents’ choice of a web survey is a function of how this option is introduced to them. A program’s parents will be randomly assigned to one of two groups to complete the parent survey: (1) a web-first group or (2) a choice group. The web-first group will receive a web-based survey initially with computer-assisted telephone interviewing (CATI) follow-up after three weeks. The choice group will receive the option of either web-based or CATI administration starting at the beginning of data collection. If parents in the web-first group do not complete the survey within the first three weeks of receiving the invitation, we will actively call them to attempt to complete the survey and send follow-up reminder materials indicating that they can now call in to complete their survey over the phone. Parents in the choice group will have the option to complete the survey on the web or phone. In the first three weeks after parents receive the invitation, we will use a passive telephone effort in which we will complete surveys only with parents who call in to Mathematica’s phone center. This will allow us to determine the parents’ choice of mode. After three weeks, we will actively begin efforts to reach parents by phone to complete the survey. We anticipate a response rate of 86 percent in the fall and 75 percent in the spring among sampled families, with approximately 40 percent of the parent surveys completed online and the remainder by telephone. In FACES 2009, the parent completion rate was 93 percent in fall 2009 (in person and by telephone) and 86 percent in spring 2010 (by telephone only).
We will send parents an email or hard copy invitation (parents who provide an email address on their consent form will receive the email) approximately two weeks before the start of data collection to invite them to complete the survey. The invitations for the parents in the web-first group will contain an Internet web address, login id, and password for completing the survey online (Appendix H-2 [email], H-3 [hard copy]). The invitations for the parents in the choice group will also contain an Internet web address, login id, and password for completing the survey online as well as a toll-free telephone number should they choose to complete the survey by phone (Appendix H-4 [email], H-5 [hard copy]). If needed, we will send parents an email or hard copy letter approximately three weeks after the start of data collection to remind them to complete the survey. The reminders for parents in the web-first group will contain the same information provided in their invitation as well as the toll-free telephone number offering them the option to complete the survey by phone (Appendix H-6 [email], H-7 [hard copy]). The reminders for parents in the choice group will contain the same information as their invitation (Appendix H-8 [email], H-9 [hard copy]). Telephone interviewing will be conducted as needed, either beginning with any call-ins by parents after receipt of these letters or approximately three weeks after the field visit week as part of follow-up.
Before the field visit, we will discuss center and family access to computers and the internet with the on-site coordinator. We will also determine the feasibility of setting up a computer station for parents to complete the survey during the field visit. During the weeklong site visits, field staff will be able to use SmartField, a web-based application for case management, to identify parents who have not yet completed their survey and encourage them to complete it.
Head Start core parent supplemental surveys (Attachment 5). Head Start parents will also complete supplemental survey questions within the core parent surveys to gather background information or additional content. These supplemental questions, requiring about 5 minutes, would follow the same procedures as described above for the core parent surveys.
Head Start core teacher child report (TCR) (Attachment 6). Head Start teachers will be asked to complete a TCR for each consented FACES child in their classroom. The study team will send teachers a letter containing an Internet web address, login ID, and password for completing the TCRs online (Appendix H-10). During the onsite field visit, field interviewers will have hard copies of the TCR forms for teachers who would prefer to complete the forms with paper and pencil. Each TCR is expected to take approximately 10 minutes to complete. We anticipate teachers will have approximately 10 FACES children in each classroom. We expect a response rate of 93 percent of TCR forms in the fall and at least 83 percent in the spring for the sampled children. Based on experience with FACES 2009, we expect 75 percent of the TCR forms will be completed by web. In FACES 2009, the TCR response rate was 97 percent in fall 2009 and 96 percent in spring 2010.
Head Start core teacher survey. On average, each teacher survey will be approximately 30 minutes long. It will be a self-administered web instrument with a paper-and-pencil option. These cases will be released during the center’s spring data collection. We anticipate a response rate of 83 percent (with 75 percent of those completed by web and the remaining 25 percent by paper). In FACES 2009, the teacher completion rate was at least 94 percent (completed as in-person interviews).
Head Start core program director survey. On average, each program director survey will be approximately 15 minutes in length. It will be a self-administered web instrument with a paper-and-pencil option. These cases will be released in the spring at the beginning of the spring data collection period. We anticipate a 100 percent response rate, with 75 percent completed by web and the remaining 25 percent by paper. All program directors completed the interview in FACES 2009.
Head Start core center director survey. On average, each center director survey will be approximately 15 minutes in length. It will be a self-administered web instrument with a paper-and-pencil option. These cases will be released during the center’s spring data collection visit week. We anticipate a response rate of 100 percent, with 75 percent completed by web and the remaining 25 percent by paper. There was a 100 percent response rate in FACES 2009.
Head Start Plus study qualitative interviews for plus study. Head Start staff or parents may be selected for Plus topical modules or special studies that would involve qualitative interviews. These interviews would last approximately one hour and would follow a semi-structured protocol. Interviews will be conducted over the phone by either a FACES liaison or Mathematica’s Survey Operation Center.
Head Start child assessment, parent survey, parent supplemental survey, and teacher child report for plus study. Additional Head Start children, parents, and teachers may be selected for Plus topical modules or special studies. Child assessments, requiring about 45 minutes, parent surveys and supplemental surveys requiring about 20 minutes and 5 minutes respectively, as well as teacher child reports, requiring about 10 minutes, would follow the same procedures as described above for the core child assessments, parent surveys, and teacher child reports.
Head Start staff surveys for plus study. Additional Head Start teachers, program directors, and center directors may be selected for Plus topical modules or special studies. Teacher surveys, requiring about 30 minutes, program director surveys requiring about 15 minutes, as well as center director surveys, requiring about 15 minutes, would follow the same procedures as described above for the Head Start staff surveys.
Early care and education administrators and providers surveys for plus study. Additional early care and education administrators and providers (such as education coordinators or family service staff) may be sampled for plus studies. These surveys would last approximately 30 minutes to gather background information or additional content on a particular topic.
B.3. Methods to Maximize Response Rates and Data Reliability
There is an established, successful record of gaining program cooperation and obtaining high response rates with center staff, children, and families in research studies of Head Start, Early Head Start, and other preschool programs. To achieve high response rates, we will continue to use the procedures that have worked well on FACES 2009, such as multi-mode approaches, e-mail as well as hard copy reminders, and tokens of appreciation. Because multiple attempts to locate parents and obtain responses leads to increased cost the longer data collection goes on, we will offer a $5 bonus for parents who complete their survey within the first three weeks of being asked to do so. We will also update some of the components with improved technology, such as tablet computers or web-based applications. Marginal response rates for FACES 2009 ranged from 93 percent to 100 percent across instruments. As outlined in a previous OMB clearance package for program recruitment, ACF will send a letter to selected programs, signed by Maria Woolverton (the federal project officer) and a member of the senior staff at OHS describing the importance of the study, outlining the study goals, and encouraging their participation. Head Start program staff and families will be motivated to participate because they are vested in the success of the program. Should programs or centers be reluctant to participate in the study, Mathematica senior staff will contact them to encourage their participation. In FACES 2009, program response rates exceeded 95 percent.
Additionally, the study team will send correspondence to remind Head Start staff and parents about upcoming surveys (Appendix H) and child assessments (Appendix C-4). The web administration of Head Start staff and parent surveys will allow the respondents to complete the surveys at their convenience. The study team will ensure that the language of the text in study forms and instruments are at a comfortable reading level for respondents. Paper-and-pencil survey options will be available for Head Start staff who have no computer or Internet access, and parent surveys can be completed via computers available at the center during the data collection visit or by telephone. CATI and field staff will also be trained on refusal conversion techniques.
These approaches, most of which have been used in prior rounds of FACES, will help ensure a high level of participation. Obtaining the high response rate we expect to attain makes the possibility of nonresponse bias less likely, which in turn makes our conclusions more generalizable to the Head Start population. We will calculate both unweighted and weighted, marginal and cumulative, response rates at each stage of sampling and data collection. Following the American Association for Public Opinion Research (AAPOR) industry standard for calculating response rates, the numerator of each response rate will include the number of eligible completed cases. We define a completed instrument as one in which all critical items for inclusion in the analysis are complete and within valid ranges. The denominator will include the number of eligible selected cases.
B.4. Test of Procedures or Methods
Most of the scales and items in the proposed parent survey, child assessment, and teacher child reports have been successfully administered in FACES 2009. We plan to conduct usability pretests with fewer than 10 respondents to test new devices, such as tablet computers, new modes, and to assess the timing of the updated, streamlined instruments.
B.5. Individuals Consulted on Statistical Methods
The team is led by Maria Woolverton, federal contracting officer’s representative (COR); Dr. Jerry West, project director; Dr. Louisa Tarullo and Dr. Nikki Aikens, co-principal investigators; and Annalee Kelly, survey director. Additional staff consulted on statistical issues include Barbara Carlson, a senior statistician at Mathematica, and Dr. Margaret Burchinal, a consultant to Mathematica on statistical and analytic issues.
1 We will work with the Office of Head Start (OHS) to update the list of programs before finalizing the sampling frame. Grantees and programs that were known by OHS to have lost their funding or otherwise closed between summer 2013 and winter 2014 will be removed from the frame, and programs associated with new grants awarded since then will be added to the frame.
2 The process of “freshening” a sample of students has been used for many NCES longitudinal studies. The freshening of the program sample for FACES 2014–2018 will use well-established methods that ensure that the refreshed sample can be treated as a valid probability sample.
3 The procedure offers all the advantages of the systematic sampling approach but eliminates the risk of bias associated with that approach. The procedure makes independent selections within each of the sampling intervals while controlling the selection opportunities for units crossing interval boundaries. Chromy, J.R. “Sequential Sample Selection Methods.” Proceedings of the Survey Research Methods Section of the American Statistical Association. Alexandria, VA: American Statistical Association, 1979, pp. 401–406.
4 If the number of children per class is not available at the time of classroom sampling, we will randomly sample three classrooms and then randomly subsample two for initial release. If these two classrooms are not likely to yield 20 children, we will release the third classroom as well.
5 We will stochastically round the stratum sizes as needed.
6 If parents do not provide an email address, we will send hard copy invitations for the parent survey.
7 Plus studies may also include additional participants completing Core instruments such as direct child assessments or parent or staff surveys.
| File Type | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
| File Title | FACES 2014_2018 Data OMB Part B |
| Author | Mathematica Staff |
| File Modified | 0000-00-00 |
| File Created | 2021-01-27 |
© 2026 OMB.report | Privacy Policy