Appendix B Analysis Nonresponse_FINAL
Appendix B Analysis Nonresponse_FINAL.docx
National Survey of Early Care and Education (NSECE)
Appendix B Analysis Nonresponse_FINAL
OMB: 0970-0391
Outline for
Report on Analysis of Nonresponse and Nonresponse Bias
in the
National Survey of Early Care and Education
1. Introduction to the National Survey of Early Care and Education
2. Unit Nonresponse in the NSECE
In this section, unit nonresponse rates will be presented for each survey. In addition, for each survey, nonresponse rates will be tabulated and displayed by the mode of data collection, by state, or by tracts (for the household survey) and provider clusters for the two provider surveys. Nonresponse rates will also be tabulated and displayed by income stratum for the household survey and provider stratum for the center-based provider survey and the workforce survey. Although high nonresponse rates do not necessarily imply large nonresponse bias (see Groves, 2006), we will examine nonresponse bias by surveys, locales, and strata wherever possible. We will identify strata and locales where nonresponse rates are the highest and investigate these in more detail when conducting nonresponse bias.
2.1 Household Survey
By mode
2.2 Home-Based Provider Survey
By mode
2.3 Center-Based Provider Survey
By mode
2.4 Workforce Survey
By mode
3. Nonresponse Bias
For
years, survey statisticians have proposed statistical models that
link bias in estimates with nonresponse. The basic underlying
premise is that nonresponders (m) may be different from responders
(r) on characteristics associated with key variables measured in the
survey. A deterministic model assumes that all members of the target
population (N) are either certain to respond (R) or certain not to
respond (M). In other words, N is the sum of M and R. Bias is
quantified as the product of the nonresponse rate (M/R) and the
difference in populations means (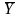 )
or other statistics between respondents and nonrespondents (Biemer &
Lyberg, 2003; Groves, 1989).
)
or other statistics between respondents and nonrespondents (Biemer &
Lyberg, 2003; Groves, 1989).
The formula below is for the deterministic model.
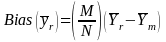
(1)
Mathematically
speaking, formula (1) is equivalent to the differences between the
population mean
for
the full sample and
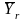 (the
mean for respondents only). Below, we outline three different methods
to evaluate nonresponse bias; each method makes a different
assumption on
and
.
(the
mean for respondents only). Below, we outline three different methods
to evaluate nonresponse bias; each method makes a different
assumption on
and
.
3.1 Using Sampling Frame Data
The first method used to examine the nonresponse bias is to take advantage of sampling frame data that are available for both respondents and nonrespondents. The Household survey sample, for instance, is selected in three stages. The first stage sampling unit (PSU) is county or county clusters and the secondary sampling unit (SSU) is census tract. SSU-level data are available from the Decennial Census and the 5-year American Community Survey (ACS) such as hard-to-count scores of the tracts, the number of households having a child less than 13, percent of households below 250% of DHHS poverty guidelines, percent of population that do not speak English and so on. The SSU-level data then can be attached to all sampled addresses in the SSUs. Nonresponse bias due to nonresponse to the household screener can be calculated using formula (1) of the deterministic model on these SSU-level data, where M stands for nonrespondents to the Household Screener and N stands for all sampled addresses.
Alternatively,
we know, for each SSU,
from either the Decennial Census or 5-year ACS data. We can also
calculate
using the completed screening interviews. The differences between
these two means will be the nonresponse bias at the SSU level.
Nonresponse bias due to nonresponse to the main household interview can be calculated similarly, where M will refer to those households who are screened in as eligible but fail to respond to the main Household interview and R will refer to those households who are screened in as eligible and who do respond to the main Household interview. In addition, screener data are available for both respondents and nonrespondents to the main Household interview and we can calculate nonresponse bias due to nonresponse to the main interview using the screener data.
For the Center-based Provider survey and Home-based Provider survey (for providers coming from administrative records), administrative data such as capacity and age ranges of the children served are available for certain types of providers and for certain states. Wherever information is available, we can compare responding providers and nonresponding providers on these variables to study nonresponse bias.
Home-Based Providers can also be spawned through the Household Screener. As a result, we have available information for all eligible providers of this type such as the number of adults living in the households and the number of children under the age of 13, and the number of adults in the household who qualify as home-based providers. These pieces of information are available for both responding and nonresponding providers, and, thus, nonresponse bias in these variables can be estimated. Another variable of interest will be whether or not the provider is co-resident with children under age 13 (and therefore in a household eligible for the Household Survey).
The sample for the workforce survey is selected from a roster of staff working directly with children in a randomly selected classroom in the completed center interviews. Information such as number of hours working each week, title, and wages is available for all rostered staff who have worked in the same classroom as the selected workforce respondents. Therefore, we can compare workforce respondents to nonresponding staff who were selected for the workforce study but have not completed the interview on these variables to examine possible bias due to nonresponse. In addition, we can look at the characteristics of the providers from which the workforce respondents have been selected. In this case, we have the full breadth of data from the center-based provider questionnaire available for analyses. We envision program size and type, the number of classrooms, and the percentage of staff who are teachers (as opposed to aides or assistant teachers) to be relevant variables for comparisons.
3.2 Level-of-Effort Analysis
The second method is the so-called level-of-effort analysis, which is often used when there are not enough data on the sampling frame data or external information is simply not available for comparison. With the level of effort analysis, respondents who have required different levels of recruitment effort are contrasted. For instance, survey responses of respondents who required refusal conversion efforts will be compared with respondents who complied with the survey request without the need of conversion. This method is based on the assumption that respondents who respond less readily are more like nonrespondents. We plan to conduct these level-of-effort analyses for all four surveys and the Household Screener to complete our understanding of potential nonresponse bias.
3.3 Comparison to the External Data Sets
Sometimes, external datasets are available that provide national or local estimates of some variables. For instance, national estimates of program sizes for Head Start programs are available and we can compare our estimates derived from our completed interviews to the national estimate to calculate potential nonresponse bias.
Another example is the estimates of teacher-student ratio available from some market rates studies. We can compare our estimates to those external estimates to get a sense of possible nonresponse bias. However, results from this method should be studied with caution as any different design parameters could contribute to this difference rather than just nonresponse.
4. NSECE Weighting
Given the multi-stage clustering design, the NSECE weights will include a selection weight to compensate for unequal selection probabilities at each stage, a nonresponse adjustment factor, and, lastly, a post-stratification weight to a known control total.
As part of nonresponse bias analysis, we will evaluate the impact of our nonresponse adjustments on the reduction of nonresponse bias. For each survey, we will calculate estimates on several variables where external information is available first using weights before nonresponse adjustment and compare them to the external benchmarks. Then we will recalculate the estimates using nonresponse-adjusted weights and compare them to the external data. Smaller differences in the second comparisons suggest that our nonresponse adjustment succeeds in reducing nonresponse bias.
5. Conclusions and Limitations
Appendix A: Distribution of Children across Response Categories
Appendix B: Demographic Distribution of Sample Children v. Benchmarks
Appendix C: Distribution of Providers across Response Categories
Appendix D: Distribution of Providers v. Benchmarks
| File Type | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
| Author | Department of Health and Human Services |
| File Modified | 0000-00-00 |
| File Created | 2021-02-01 |
© 2026 OMB.report | Privacy Policy